- 자바 프로그래밍(com.eomcs.io)
- 바이너리 파일 입출력 다루기(ex02)
- 바이트 스트림으로 텍스트 입출력하기Byte Stream - 텍스트 출력 하기
Exam0510.java
package com.eomcs.io.ex02;
import java.io.FileOutputStream;
public class Exam0510 {
public static void main(String[] args) throws Exception {
String str = new String("AB가각");
// String 객체의 데이터를 출력하려면
// 문자열을 담은 byte[] 배열을 리턴 받아야 한다.
// JVM에 문자를 입출력할 때 사용하는 기본 문자 집합이 무엇인지 알아 본다.
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
byte[] bytes = str.getBytes(); // 문자집합을 지정하지 않으면 file.encoding에 설정된 문자집합으로 인코딩하여 리턴한다.
//
// 이클립스:
// UCS2 ==> UTF-8
// 이클립스의 경우 자바 앱을 실행할 때 file.encoding 변수의 값을 utf-8 로 설정한다.
//
// file.encoding JVM 환경 변수의 값이 설정되어 있지 않을 경우,
// Windows: UCS2 ==> MS949
// Linux: UCS2 ==> UTF-8
// macOS: UCS2 ==> UTF-8
//
for (byte b : bytes) {
System.out.printf("%x ", b);
}
System.out.println();
// 바이트 배열 전체를 그대로 출력한다.
FileOutputStream out = new FileOutputStream("temp/utf.txt");
out.write(bytes);
out.close();
System.out.println("데이터 출력 완료!");
}
}
String 객체의 데이터를 출력하려면
문자열을 담은 byte[] 배열을 리턴 받아야 한다.
String.getBytes()
=> 특정 인코딩을 지정하지 않고 그냥 바이트 배열을 달라고 하면,
String 클래스는 JVM 환경 변수 'file.encoding' 에 설정된 문자집합으로
바이트 배열을 인코딩 한다.
=> 이클립스에서 애플리케이션을 실행할 때 다음과 같이 JVM 환경변수를 자동으로 붙인다.
$ java -Dfile.encoding=UTF-8 ....
=> 그래서 getBytes()가 리턴한 바이트 배열의 인코딩은 UTF-8이 되는 것이다.
=> 만약 이 예제를 이클립스가 아니라 콘솔창에서
-Dfile.encoding=UTF-8 옵션 없이 실행한다면,
getBytes()가 리턴하는 바이트 배열은
OS의 기본 인코딩으로 변환될 것이다.
=> OS 기본 인코딩
Windows => MS949
Linux/macOS => UTF-8
=> OS에 상관없이 동일한 실행 결과를 얻고 싶다면, 다음과 같이 file.encoding 옵션을 붙여라
$ java -Dfile.encoding=UTF-8 -cp bin/main .....
=> 또는 getBytes() 호출할 때 인코딩할 문자집합을 지정하라.
str.getBytes("UTF-8")
JVM에 문자를 입출력할 때 사용하는 기본 문자 집합이 무엇인지 알아 본다.ㄴ 윈도우인 경우 MS-949 로 출력되며, 데이터는 41 42 b0 a1 b0 a2 로 출력됨
=> 아래처럼 해야함
=> 이게 안 된다면,
=> PowerShell 에서 실행 시 아래처럼 해야함
이클립스는 옵션이 주어져있으므로 윈도우에서 실행해도 UTF-8 로 인코딩되어 실행됨
ㄴ Run > RunConfigurations... 선택
=>
ㄴ [Show Command Line] 선택
=>
ㄴ -Dfile.encoding=UTF-8 확인
Byte Stream - 텍스트 출력 하기
UCS2 ==> EUC-KR 로 인코딩
Exam0511.java
// Byte Stream - 텍스트 출력 하기
package com.eomcs.io.ex02;
import java.io.FileOutputStream;
public class Exam0511 {
public static void main(String[] args) throws Exception {
String str = new String("AB가각");
// String 객체의 데이터를 출력하려면
// 문자열을 담은 byte[] 배열을 리턴 받아야 한다.
// => MS949로 인코딩 하기
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
byte[] bytes = str.getBytes("EUC-KR"); // UCS2 ==> EUC-KR
for (byte b : bytes) {
System.out.printf("%x ", b);
}
System.out.println();
// 바이트 배열 전체를 그대로 출력한다.
FileOutputStream out = new FileOutputStream("temp/ms949.txt");
out.write(bytes);
out.close();
System.out.println("데이터 출력 완료!");
}
}
UTF-16BE 로 인코딩
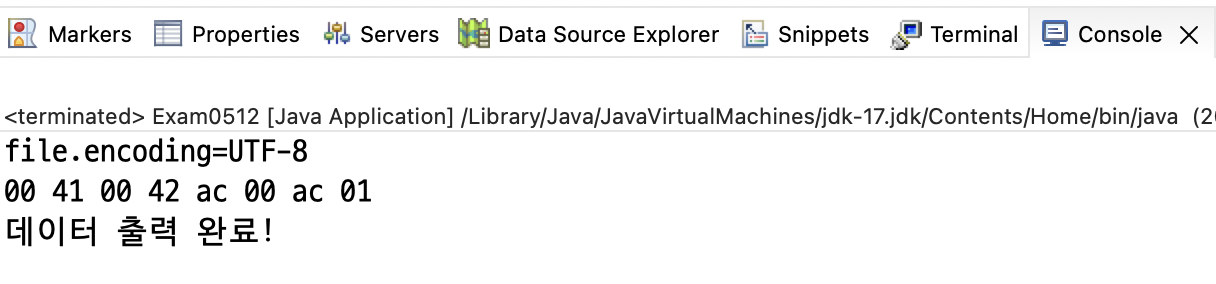
Exam0512.java
// Byte Stream - 텍스트 출력 하기
package com.eomcs.io.ex02;
import java.io.FileOutputStream;
public class Exam0512 {
public static void main(String[] args) throws Exception {
String str = new String("AB가각");
// String 객체의 데이터를 출력하려면
// 문자열을 담은 byte[] 배열을 리턴 받아야 한다.
// => UTF-16BE로 인코딩 하기
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
byte[] bytes = str.getBytes("UTF-16BE"); // UCS2 ==> UTF-16BE
for (byte b : bytes) {
System.out.printf("%02x ", b);
}
System.out.println();
// 바이트 배열 전체를 그대로 출력한다.
FileOutputStream out = new FileOutputStream("temp/utf16be.txt");
out.write(bytes);
out.close();
System.out.println("데이터 출력 완료!");
}
}
UTF-8-16LE 로 인코딩
Exam0513.java
// Byte Stream - 텍스트 출력 하기
package com.eomcs.io.ex02;
import java.io.FileOutputStream;
public class Exam0513 {
public static void main(String[] args) throws Exception {
String str = new String("AB가각");
// String 객체의 데이터를 출력하려면
// 문자열을 담은 byte[] 배열을 리턴 받아야 한다.
// => UTF-16LE로 인코딩 하기
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
byte[] bytes = str.getBytes("UTF-16LE"); // UCS2 ==> UTF-16LE
for (byte b : bytes) {
System.out.printf("%02x ", b);
}
System.out.println();
// 바이트 배열 전체를 그대로 출력한다.
FileOutputStream out = new FileOutputStream("temp/utf16le.txt");
out.write(bytes);
out.close();
System.out.println("데이터 출력 완료!");
}
}
UCS2 ==> UTF-8로 인코딩
Exam0514.java
// Byte Stream - 텍스트 출력 하기
package com.eomcs.io.ex02;
import java.io.FileOutputStream;
public class Exam0514 {
public static void main(String[] args) throws Exception {
String str = new String("AB가각");
// String 객체의 데이터를 출력하려면
// 문자열을 담은 byte[] 배열을 리턴 받아야 한다.
// => UTF-8로 인코딩 하기
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
byte[] bytes = str.getBytes("UTF-8"); // UCS2 ==> UTF-8
for (byte b : bytes) {
System.out.printf("%x ", b);
}
System.out.println();
// 바이트 배열 전체를 그대로 출력한다.
FileOutputStream out = new FileOutputStream("temp/utf8.txt");
out.write(bytes);
out.close();
System.out.println("데이터 출력 완료!");
}
}
ㄴ 추천 방식 : UTF-8
ms949 로 인코딩
Exam0520.java
// Byte Stream - 텍스트 데이터 읽기
package com.eomcs.io.ex02;
import java.io.FileInputStream;
public class Exam0520 {
public static void main(String[] args) throws Exception {
FileInputStream in = new FileInputStream("sample/ms949.txt");
int b = 0;
// MS949로 인코딩된 텍스트 읽기
// - 단순히 1바이트를 읽어서는 안된다.
// - 영어는 1바이트를 읽으면 되지만,
// 한글은 2바이트를 읽어야 한다.
while ((b = in.read()) != -1) {
if (b >= 0x81) { // 읽은 바이트가 한글에 해당한다면
// 1바이트를 더 읽어서 기존에 읽은 바이트 뒤에 붙여 2바이트로 만든다.
b = b << 8 | in.read();
}
System.out.printf("%x\n", b);
}
in.close();
}
}
ASCII 코드와 한글 코드 읽기
Exam0521.java
// Byte Stream - 텍스트 데이터 읽기 II
package com.eomcs.io.ex02;
import java.io.FileInputStream;
public class Exam0521 {
public static void main(String[] args) throws Exception {
// JVM 환경 변수 'file.encoding' 값
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
FileInputStream in = new FileInputStream("sample/utf8.txt");
// 파일의 데이터를 한 번에 읽어보자.
byte[] buf = new byte[1000];
int count = in.read(buf); // <== 41 42 ea b0 80 ea b0 81 (AB가각)
in.close();
// 읽은 바이트 수를 출력해보자.
System.out.printf("읽은 바이트 수: %d\n", count);
// 읽은 바이트를 String 객체로 만들어보자.
// - 바이트 배열에 저장된 문자 코드를
// JVM이 사용하는 문자 집합(UCS2=UTF16BE)의 코드 값으로 변환한다.
// - 바이트 배열에 들어 있는 코드 값이 어떤 문자 집합의 값인지 알려주지 않는다면,
// JVM 환경 변수 file.encoding에 설정된 문자 집합으로 가정하고 변환을 수행한다.
String str = new String(buf, 0, count);
// 바이트 배열이 어떤 문자집합으로 인코딩 된 것인지 알려주지 않으면,
// file.encoding에 설정된 문자집합으로 인코딩된 것으로 간주한다.
System.out.println(str);
// 바이트가 어떤 문자 집합으로 인코딩 되었는지 알려주지 않는다면?
// String 객체를 생성할 때 다음의 규칙에 따라 변환한다.
// => JVM 환경 변수 'file.encoding' 에 설정된 문자집합으로 가정하고 UCS2 문자 코드로 변환한다.
//
// 1) 이클립스에서 실행 => 성공!
// - JVM 실행 옵션에 '-Dfile.encoding=UTF-8' 환경 변수가 자동으로 붙는다.
// - 그래서 String 클래스는 바이트 배열의 값을 UCS2로 바꿀 때 UTF-8 문자표를 사용하여 UCS2 로 변환한다.
// - 예1)
// utf8.txt => 41 42 ea b0 80 ea b0 81
// UCS2 => 0041 0042 ac00 ac01 <== 정상적으로 바뀐다.
//
// 2) Windows 콘솔에서 실행 => 실패!
// - JVM을 실행할 때 file.encoding을 설정하지 않으면
// OS의 기본 문자집합으로 설정한다.
// - Windows의 기본 문자집합은 MS949 이다.
// - 따라서 file.encoding 값은 MS949가 된다.
// - 바이트 배열은 UTF-8로 인코딩 되었는데,
// MS949 문자표를 사용하여 UCS2로 변환하려 하니까
// 잘못된 문자로 변환되는 것이다.
// - 해결책?
// JVM을 실행할 때 file.encoding 옵션에 정확하게 해당 파일의 인코딩을 설정하라.
// 즉 utf8.txt 파일은 UTF-8로 인코딩 되었기 때문에
// '-Dfile.encoding=UTF-8' 옵션을 붙여서 실행해야 UCS2로 정상 변환된다.
//
// 3) Linux/macOS 콘솔에서 실행 => 성공!
// - Linux와 macOS의 기본 문자 집합은 UTF-8이다.
// - 따라서 JVM을 실행할 때 '-Dfile.encoding=UTF-8' 옵션을 지정하지 않아도
// 해당 파일을 UTF-8 문자로 간주하여 UTF-8 문자표에 따라 UCS2로 변환한다.
//
}
}
ㄴ 윈도우 PowerShell 에서 실행하면 깨지는 경우 : 운영체제의 기본 인코딩이 MS-949 로 설정되어있기 때문
=> byte 배열이 문제가 아니라 어떤 character set 으로 인코딩 됐는지 알려주지 않아서 깨지게 됨
Exam0522.java
// Byte Stream - 텍스트 데이터 읽기 II
package com.eomcs.io.ex02;
import java.io.FileInputStream;
public class Exam0522 {
public static void main(String[] args) throws Exception {
// JVM 환경 변수 'file.encoding' 값
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
FileInputStream in = new FileInputStream("sample/ms949.txt"); // 41 42 b0 a1 b0 a2(AB가각)
// 파일의 데이터를 한 번에 읽어보자.
byte[] buf = new byte[1000];
int count = in.read(buf);
in.close();
String str = new String(buf, 0, count);
// 바이트 배열에 MS949 문자집합에 따라 인코딩 된 데이터가 들어 있는데,
// String 클래스는 UTF-8 문자집합으로 인코딩 되었다고 가정하기 때문에
// UTF-16으로 정확하게 변환할 수 없는 것이다.
System.out.println(str);
// ms949.txt 파일을 읽을 때 문자가 깨지는 이유?
// - 한글이 다음과 같이 MS949 문자 집합으로 인코딩 되어 있다.
// ms949.txt => 41 42 b0 a1 b0 a2
// - String 객체를 생성할 때 바이트 배열의 문자집합을 알려주지 않으면
// JVM 환경 변수 'file.encoding'에 설정된 문자집합이라고 가정한다.
//
// 1) 이클립스에서 실행 => 실패!
// - 이클립스에서 JVM을 실행할 때 '-Dfile.encoding=UTF-8' 옵션을 붙인다.
// - 따라서 String 클래스는 바이트 배열의 값을 UCS2로 변환할 때 UTF-8 문자표를 사용한다.
// - 문제는, 바이트 배열의 값이 MS949로 인코딩 되어 있다는 사실이다.
// 즉 잘못된 문자표를 사용하니까 변환을 잘못한 것이다.
//
// 2) Windows 콘솔에서 실행 => 성공!
// - JVM을 실행할 때 'file.encoding' 환경 변수를 지정하지 않으면,
// OS의 기본 문자 집합으로 설정한다.
// - Windows의 기본 문자 집합은 MS949이다.
// - 따라서 file.encoding의 값은 MS949로 설정된다.
// - 바이트 배열의 값이 MS949 이기 때문에 MS949 문자표로 변환하면
// UCS2 문자 코드로 잘 변환되는 것이다.
//
// MS949 코드를 UTF-8 문자로 가정하고 다룰 때 한글이 깨지는 원리!
// - ms949.txt
// => 01000001 01000010 10110000 10100001 10110000 10100010 = 41 42 b0 a1 b0 a2
// - MS949 코드를 변환할 때 UTF-8 문자표를 사용하면 다음과 같이 잘못된 변환을 수행한다.
// byte(UTF-8) => char(UCS2)
// 01000001 -> 00000000 01000001 (00 41) = 'A' <-- 정상적으로 변환되었음.
// 01000010 -> 00000000 01000010 (00 42) = 'B' <-- 정상적으로 변환되었음.
// 10110000 -> 꽝 (xx xx) <-- 해당 바이트가 UTF-8 코드 값이 아니기 때문에 UCS2로 변환할 수 없다.
// 10100001 -> 꽝 (xx xx) <-- 그래서 꽝을 의미하는 특정 코드 값이 들어 갈 것이다.
// 10110000 -> 꽝 (xx xx) <-- 그 코드 값을 문자로 출력하면 => �
// 10100010 -> 꽝 (xx xx)
}
}
=> 윈도우 PowerShell 에서 실행할 경우 안 깨지는 이유 : 운영체제의 기본 인코딩이 MS-949 로 설정되어있기 때문
ㄴ 한글이 다음과 같이 MS949 문자 집합으로 인코딩 되어 있음
ms949.txt => 41 42 b0 a1 b0 a2
ㄴ String 객체를 생성할 때 바이트 배열의 문자집합을 알려주지 않으면 JVM 환경 변수 'file.encoding'에 설정된 문자집합이라고 가정함
=>
Exam0523.java
// Byte Stream - 텍스트 데이터 읽기 II
package com.eomcs.io.ex02;
import java.io.FileInputStream;
public class Exam0523 {
public static void main(String[] args) throws Exception {
// JVM 환경 변수 'file.encoding' 값
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
FileInputStream in = new FileInputStream("sample/ms949.txt");
// 파일의 데이터를 한 번에 읽어보자.
byte[] buf = new byte[1000];
int count = in.read(buf);
in.close();
// JVM 환경 변수 'file.encoding'에 설정된 문자표에 상관없이
// String 객체를 만들 때 바이트 배열의 인코딩 문자 집합을 정확하게 알려준다면,
// UCS2 코드 값으로 정확하게 변환해 줄 것이다.
String str = new String(buf, 0, count, "CP949"); // MS949 = CP949
System.out.println(str);
}
}
ㄴ 바이트 배열의 인코딩 문자 집합을 정확하게 알려주면 됨
Exam0524.java
// Byte Stream - 텍스트 데이터 읽기 II
package com.eomcs.io.ex02;
import java.io.FileInputStream;
public class Exam0524 {
public static void main(String[] args) throws Exception {
// JVM 환경 변수 'file.encoding' 값
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
FileInputStream in = new FileInputStream("sample/utf16be.txt"); // 0041 0042 ac00 ac01(AB가각)
// 파일의 데이터를 한 번에 읽어보자.
byte[] buf = new byte[1000];
int count = in.read(buf);
in.close();
// JVM 환경 변수 'file.encoding'에 설정된 문자표에 상관없이
// String 객체를 만들 때 바이트 배열의 인코딩 문자 집합을 정확하게 알려준다면,
// UCS2 코드 값으로 정확하게 변환해 줄 것이다.
String str = new String(buf, 0, count, "UTF-16"); // UTF-16 == UTF-16BE
System.out.println(str);
}
}
ㄴ 바이트 배열의 인코딩 문자 집합을 정확하게 알려주면 됨
Exam0525.java
// Byte Stream - 텍스트 데이터 읽기 II
package com.eomcs.io.ex02;
import java.io.FileInputStream;
public class Exam0525 {
public static void main(String[] args) throws Exception {
// JVM 환경 변수 'file.encoding' 값
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
FileInputStream in = new FileInputStream("sample/utf16le.txt");
// 파일의 데이터를 한 번에 읽어보자.
byte[] buf = new byte[1000];
int count = in.read(buf);
in.close();
// JVM 환경 변수 'file.encoding'에 설정된 문자표에 상관없이
// String 객체를 만들 때 바이트 배열의 인코딩 문자 집합을 정확하게 알려준다면,
// UCS2 코드 값으로 정확하게 변환해 줄 것이다.
String str = new String(buf, 0, count, "UTF-16LE");
System.out.println(str);
}
}
ㄴ 바이트 배열의 인코딩 문자 집합을 정확하게 알려주면 됨



