- 자바 프로그래밍
- JDBC 프로그래밍(com.eomcs.jdbc)
- DBMS API와 ODBC API
- JDBC API와 JDBC 드라이버
- SQL - DDL 사용법
MySQL JDBC Driver 설치
https://central.sonatype.com/?smo=true
Maven Central
# Programming Language Utilities
central.sonatype.com

=>

=>

=>
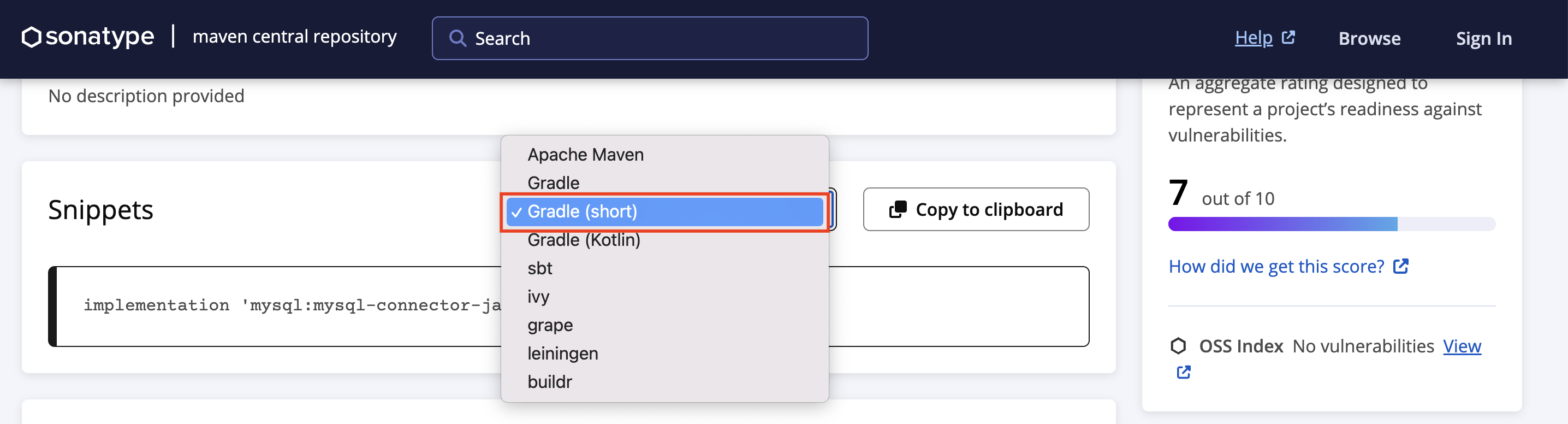
=>
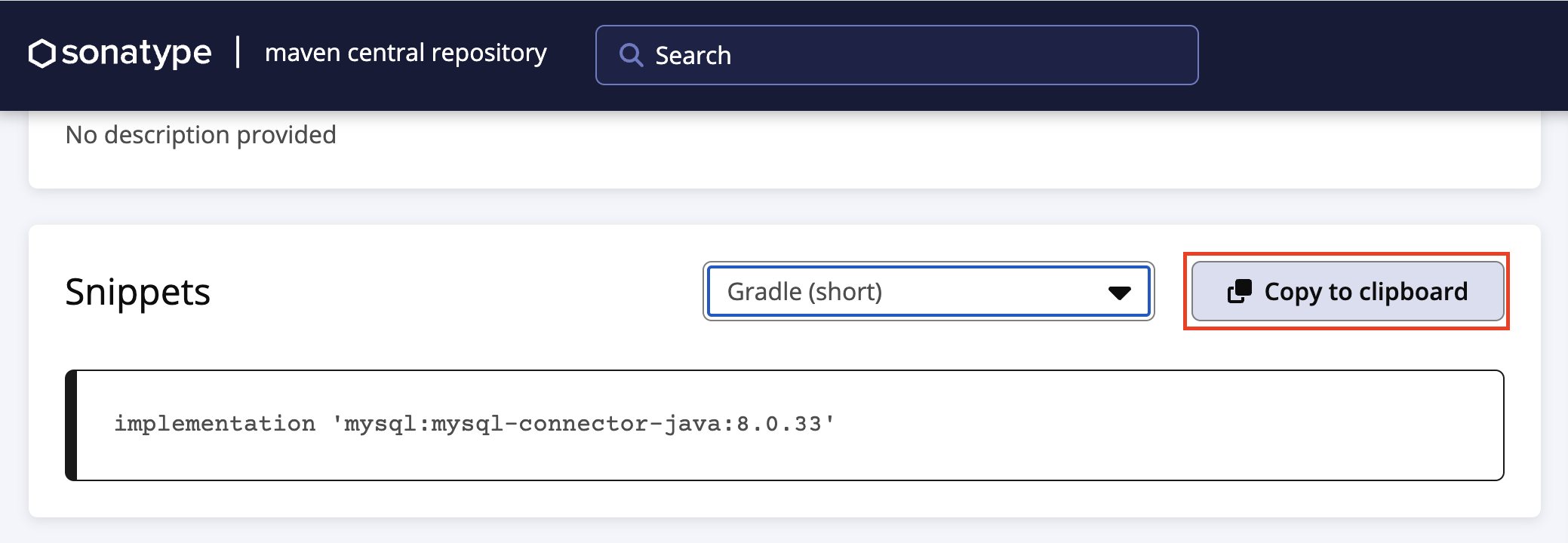
=>

ㄴ java-lang 프로젝트의 build.gradle 스크립트 파일에 붙여넣기(추가)
=>

ㄴ gradle eclipse 를 이용해 gradle 재설정
=>

ㄴ 프로젝트 Refresh 해주기
=>
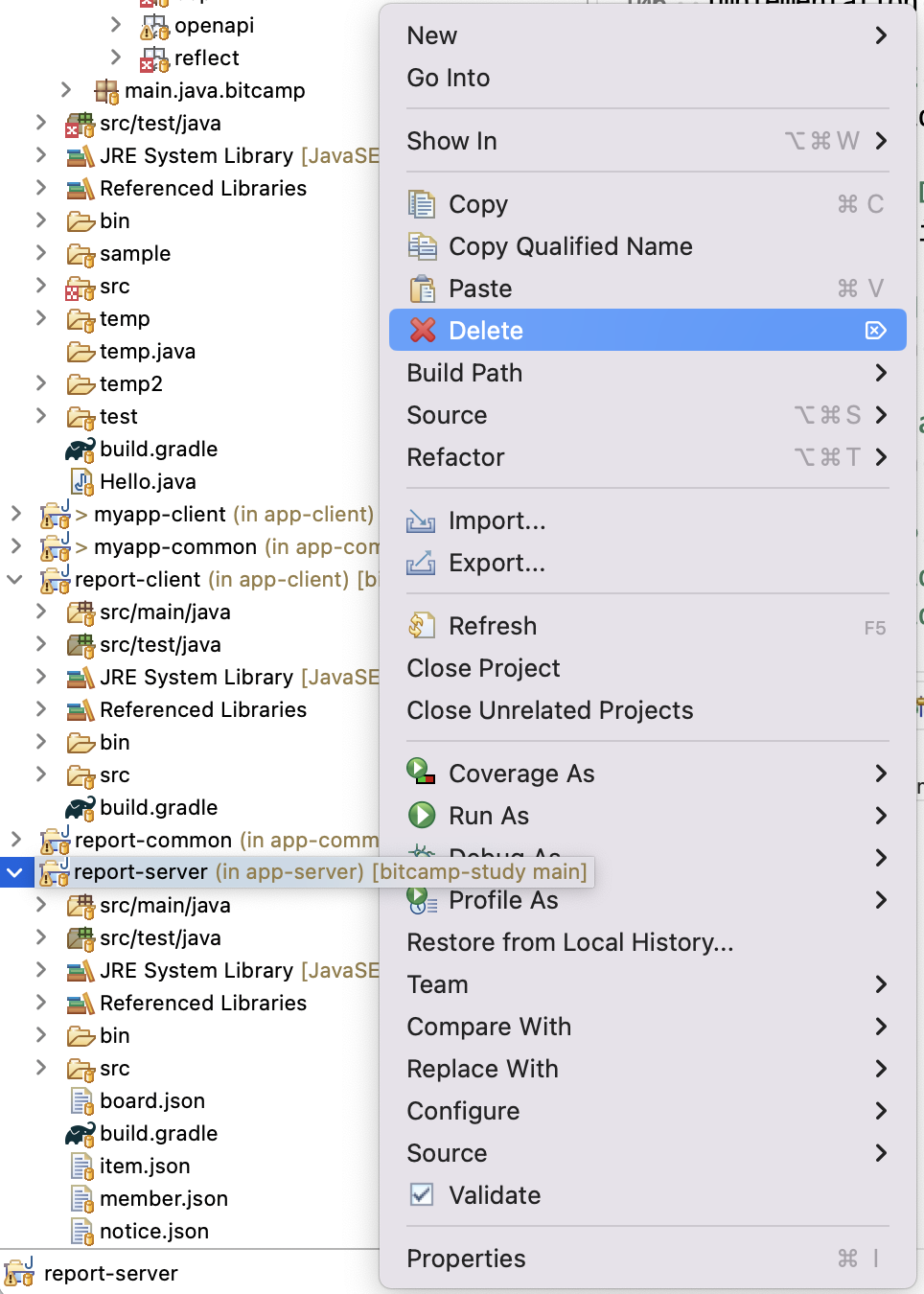
ㄴ report-server 를 workspace 에서 제거하기(실제 컴퓨터에있는 폴더를 삭제하는 것이 아님)
=>
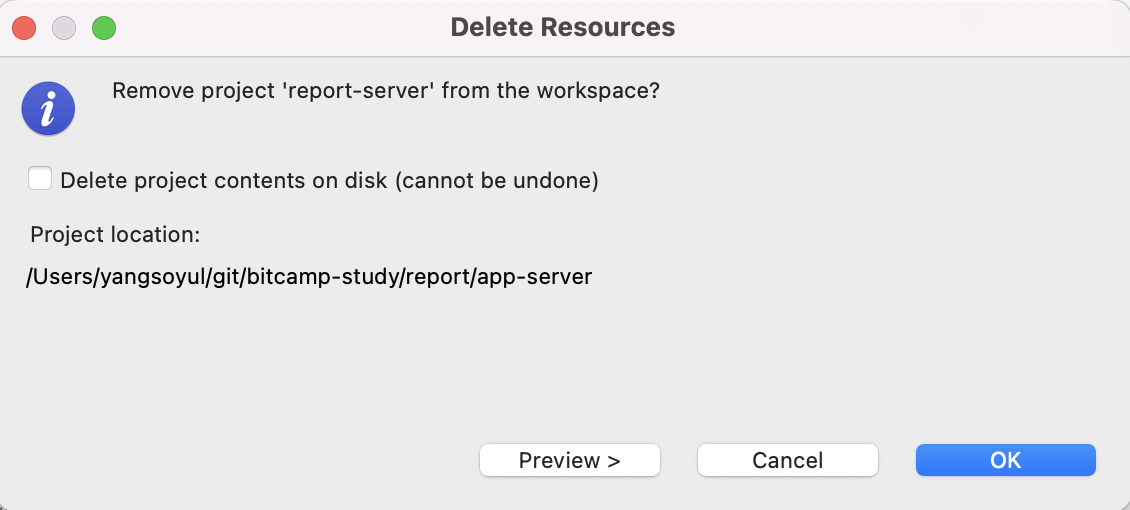
ㄴ 체크박스를 체크하면 실제 컴퓨터에있는 폴더도 완전 제거되므로 체크하지 않고 [ok] 선택
=>
build.gradle
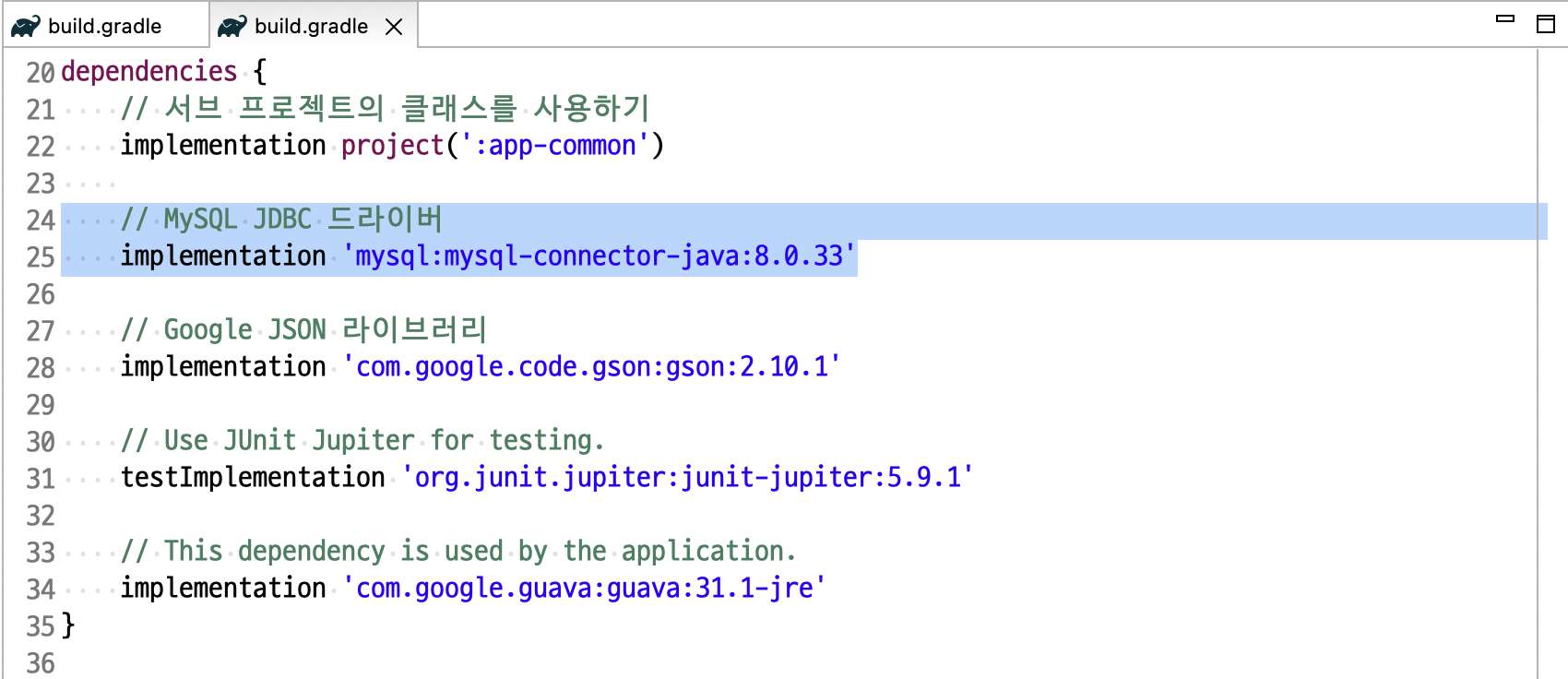
ㄴ java-lang 프로젝트의 build.gradle 스크립트 파일에 추가해던 MySQL JDBC Driver 를 report-client 에도 추가해주기
=>

ㄴ gradle eclipse 를 이용해 gradle 재설정
=>
=>

ㄴ 외부 라이브러리 목록에 mysql-connector-j-8.0.33.jar 파일이 추가됨을 확인

DDL(DataDefinition Language)
# DDL(Data Definition Language)
- DB 객체(테이블, 뷰, 프로시저, 함수, 트리거) 등을 생성, 변경, 삭제하는 SQL 명령이다.
- 데이터베이스(database) = 스키마(schema)
- 테이블(table)
- 뷰(view)
- 트리거(trigger=listener)
- 특정 조건에서 자동으로 호출되는 함수
- 특정 조건? SQL 실행 전/후 등
- OOP 디자인 패턴에서 옵저버에 해당한다.
- 함수(function)
- 프로시저(procedure)
- 인덱스(index)

ㄴ mysql 실행 => mysql -u study(사용자명) -p
ㄴ 비밀번호 입력
=> mysql 접속됨

ㄴ use studydb(데이터베이스명);
=> 해당 데이터베이스를 기본으로 사용하겠다는 명령
데이터베이스 생성, 삭제, 변경 명령
## 데이터베이스
데이터베이스 생성
create database 데이터베이스명 옵션들...;
데이터베이스 삭제
drop database 데이터베이스명;
데이터베이스 변경
alter database 데이터베이스명 옵션들...;
테이블
## 테이블
테이블 생성
create table 테이블명 (
컬럼명 타입 NULL여부 옵션,
컬럼명 타입 NULL여부 옵션,
...
컬럼명 타입 NULL여부 옵션
);
테이블 정보 보기
describe 테이블명;
desc 테이블명;
예) describe test01;
예) desc test01;
테이블 삭제하기
drop table 테이블명;
예) drop table test01;
test01 테이블 생성

=>


test01 테이블 삭제

테이블 컬럼 옵션
테이블 컬럼 null 허용
### 테이블 컬럼 옵션
#### null 허용
데이터를 입력하지 않아도 된다.test1 테이블 생성


데이터 입력 테스트
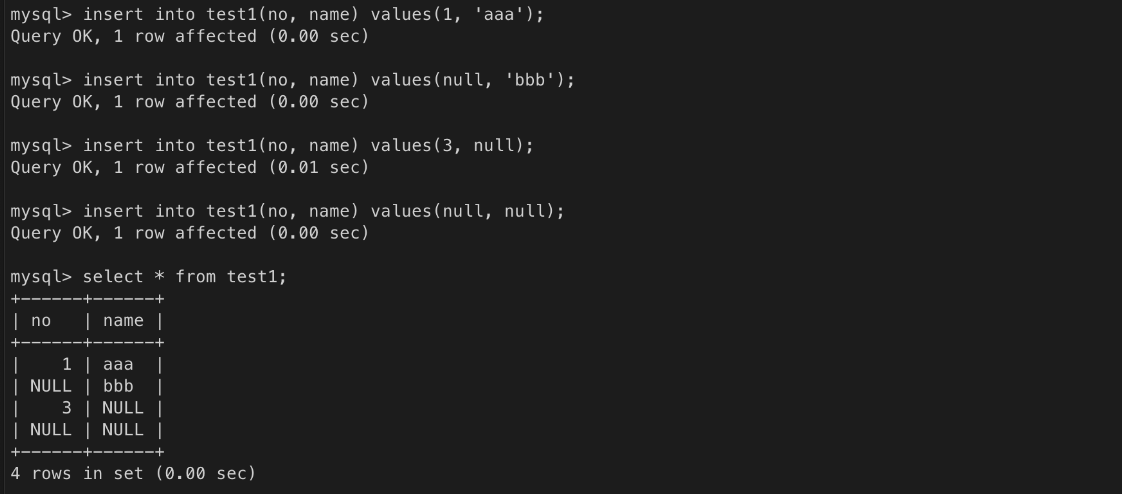
ㄴ 데이터를 입력하지 않아도 됨
=> 입력하지 않으려면 null 을 이용
테이블 컬럼 null 허용하지 않음
#### not null
데이터를 입력하지 않으면 입력/변경 거절!test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행) 및 입력 테스트

테이블 컬럼 기본값 지정하기
#### 기본값 지정하기
입력 값을 생략하면 해당 컬럼에 지정된 기본값이 대신 입력된다.test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행) 및 데이터 입력 테스트
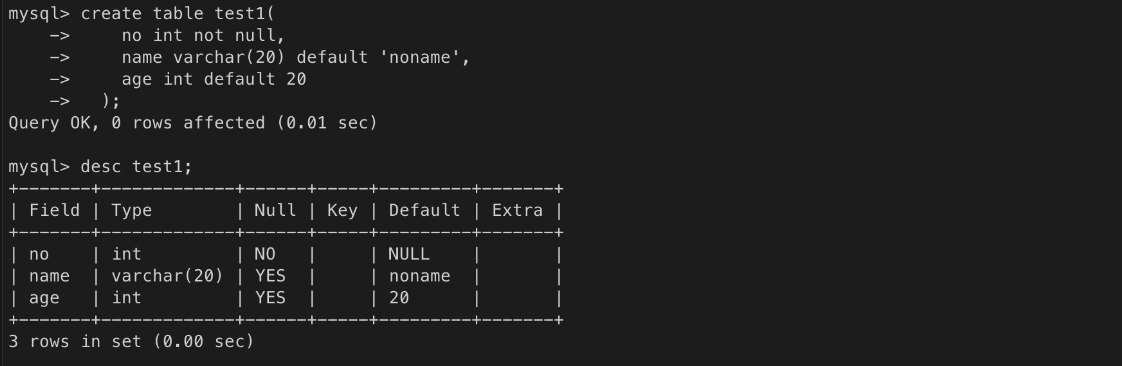

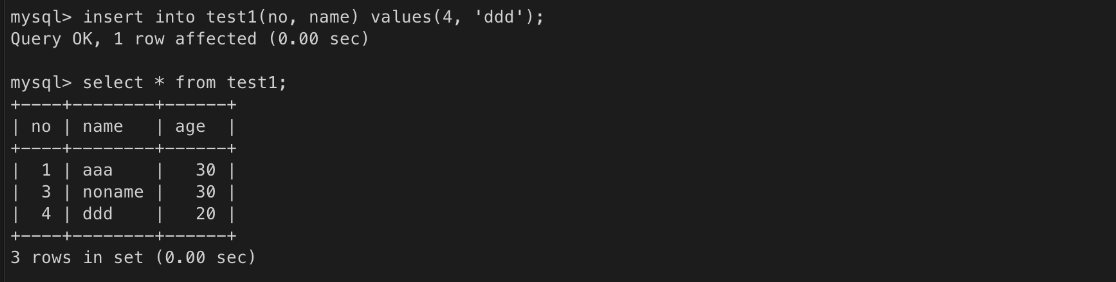

ㄴ 값을 입력하지 않는 컬럼은 이름과 값 지정을 생략함 => 오류! no는 not null
ㄴ 컬럼에 default 값이 설정된 경우, 컬럼 값의 입력을 생략하면 기본값이 사용됨
컬럼에 default 옵션이 있는 경우,
- 컬럼 값을 생략하면 default 옵션으로 지정한 값이 사용된다.
- 컬럼 값을 null로 지정하면 기본 값이 사용되지 않는다.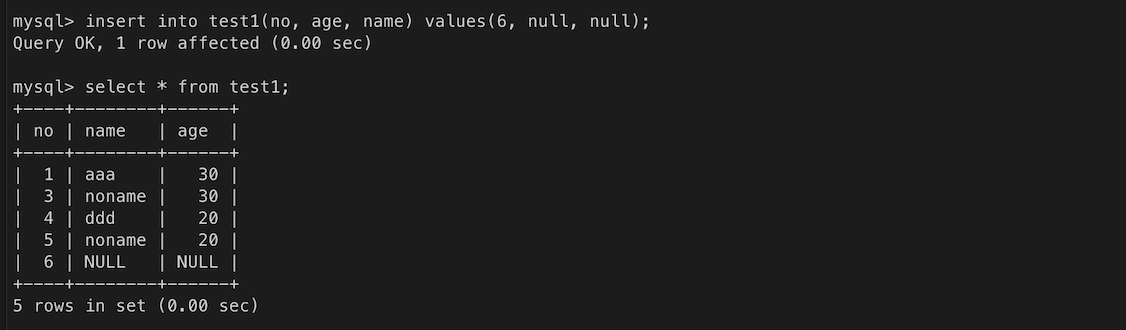
컬럼 타입
### 컬럼 타입
#### int
- 4바이트 크기의 정수 값 저장
- 기타 tinyint(1바이트), smallint(2바이트), mediumint(3바이트), bigint(8바이트)
#### float
- 부동소수점 저장
#### numeric = decimal
- 전체 자릿수와 소수점 이하의 자릿수를 정밀하게 지정할 수 있다.
- numeric(n,e) : 전체 n 자릿수 중에서 소수점은 e 자릿수다.
- 예) numeric(10,2) : 12345678.12
- numeric : numeric(10, 0) 과 같다.test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)

=>
데이터 입력 테스트
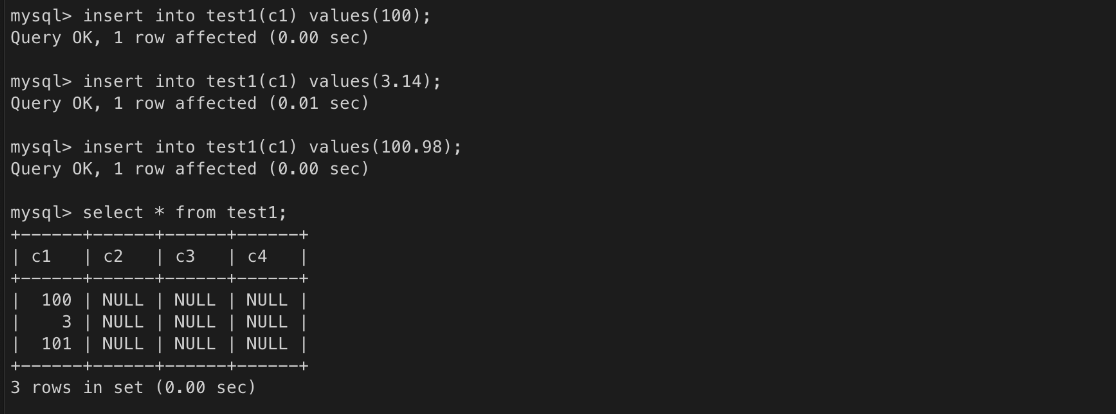
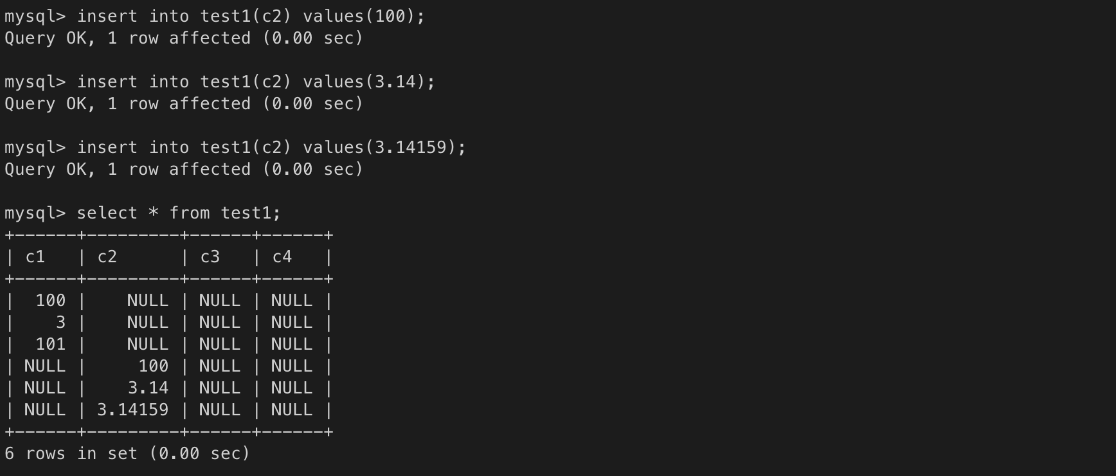
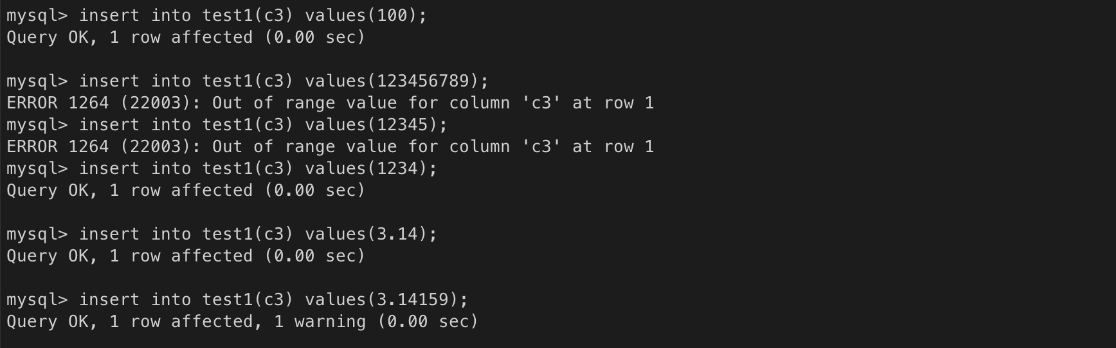
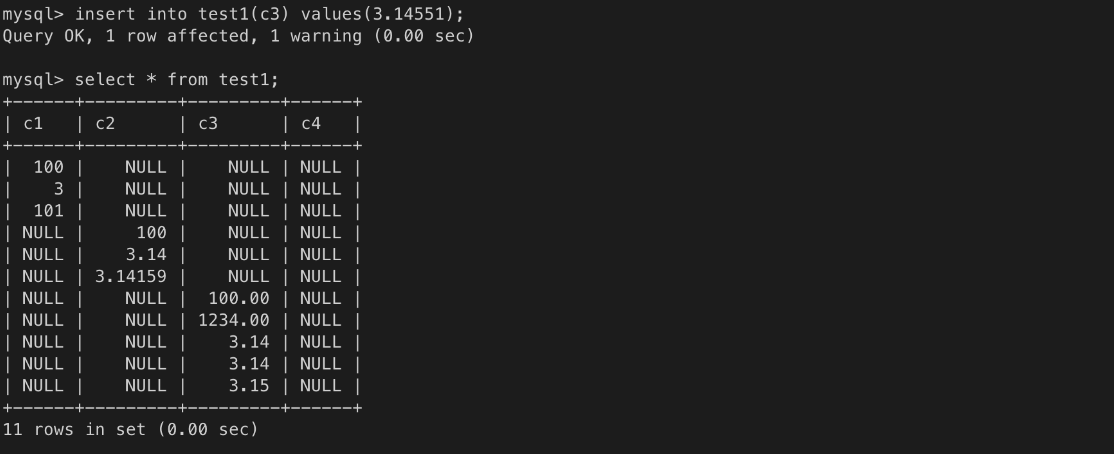

ㄴ 소수점 이하 반올림하고 짜름
ㄴ 입력 오류. 5자리 초과
ㄴ 입력 오류. 1자리 초과
ㄴ 2자리를 초과한 값은 반올림
ㄴ 소수점은 반올림 처리됨
char(n)
#### char(n)
- 최대 n개의 문자를 저장.
- 0 <= n <= 255
- 고정 크기를 갖는다.
- 한 문자를 저장하더라도 n자를 저장할 크기를 사용한다.
- 메모리 크기가 고정되어서 검색할 때 빠르다.varchar(n)
#### varchar(n)
- 최대 n개의 문자를 저장.
- 0 ~ 65535 바이트 크기를 갖는다.
- n 값은 문자집합에 따라 최대 값이 다르다.
- 한 문자에 1바이트를 사용하는 ISO-8859-n 문자집한인 경우 최대 65535 이다.
- 그러나 UTF-8로 지정된 경우는, n은 최대 21844까지 지정할 수 있다.
- 가변 크기를 갖는다.
- 한 문자를 저장하면 한 문자 만큼 크기의 메모리를 차지한다.
- 메모리 크기가 가변적이라서 데이터 위치를 찾을 때 시간이 오래 걸린다.
그래서 검색할 때 위치를 계산해야 하기 때문에 검색 시 느리다.
test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)

=>
데이터 입력 테스트

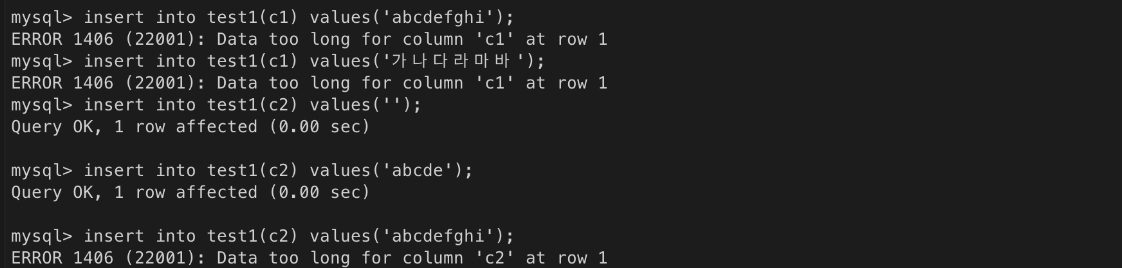
ㄴ 한글 영어 상관없이 5자 가능
ㄴ ERROR => 입력 크기 초과 오류!
고정 크기와 가변크기 비교

=>

ㄴ DBMS 중에는 고정 크기인 컬럼의 값을 비교할 때 빈자리까지 검사하는 경우도 있음
=> 즉 c1='abc'에서는 데이터를 찾지 못하고, c1='abc '여야만 데이터를 찾는 경우가 있음
ㄴ 그러나 mysql은 고정크기 컬럼이더라도 빈자리를 무시하고 데이터를 찾음
test, mediumtext, longtext
#### text(65535), mediumtext(약 1.6MB), longtext(약 4GB)
- 긴 텍스트를 저장할 때 사용하는 컬럼 타입이다.
- 오라클의 경우 long 타입과 CLOB(character large object) 타입이 있다.MySQL 매뉴얼 확인






MariaDB 매뉴얼 확인

date, time, datetime
#### date
- 날짜 정보를 저장할 때 사용한다.
- 년,월,일 정보를 저장한다.
- 오라클의 경우 날짜 뿐만 아니라 시간 정보도 저장한다.
#### time
- 시간 정보를 저장할 때 사용한다.
- 시, 분, 초 정보를 저장한다.
#### datetime
- 날짜와 시간 정보를 함께 저장할 때 사용한다.test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)

데이터 입력 테스트

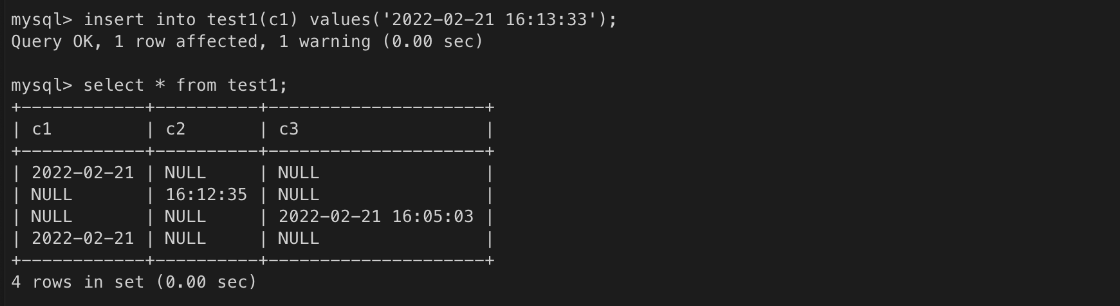



ㄴ 년월일은 생략 불가능
boolean
#### boolean
- 보통 true, false를 의미하는 값을 저장할 때는 정수 1 또는 0으로 표현한다.
- 또는 문자로 Y 또는 N으로 표현하기도 한다.
- 실제 컬럼을 생성할 때 tinyint(1) 로 설정한다.test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)

데이터 입력 테스트

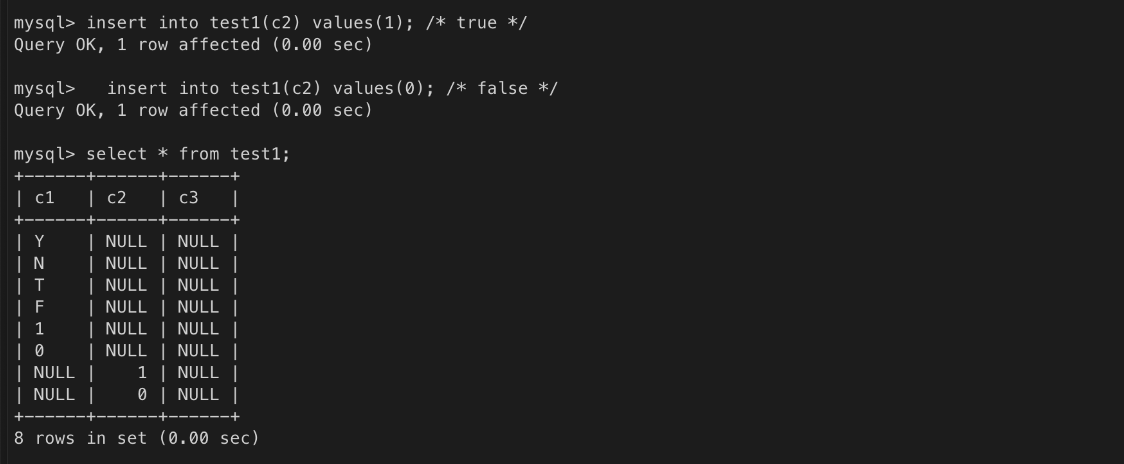


ㄴ 숫자 컬럼인 경우 값을 설정할 때 문자로 표현할 수 있음
ㄴ 즉 문자열을 숫자로 바꿀 수 있으면 됨


키 컬럼 지정
### 키 컬럼 지정
key column : 데이터를 구분할 때 사용하는 값
테이블:
- name, email, jumin, id, pwd, tel, postno, basic_addr, gender
#### key vs candidate key
- key
- 데이터를 구분할 때 사용하는 컬럼들의 집합
- 예)
- {email}, {jumin}, {id}, {name, tel}, {tel, basic_addr, gender, name}
- {name, jumin}, {email, id}, {id, name, email} ...
- candidate key (후보키 = 최소키)
- key 들 중에서 최소 항목으로 줄인 키
- {jumin}, {email}, {id}, {name, tel}
#### alternate key vs primary key
- primary key (주 키)
- candidate key 중에서 DBMS 관리자가 사용하기로 결정한 키
- 예) DBMS 관리자가 id 컬럼의 값을 데이터를 구분하는 키로 사용하기로 결정했다면,
- 주 키는, {id} 가 된다.
- 주 키로 선택되지 않은 모든 candidate key는 alternate key가 된다.
- alternate key (대안 키)
- candidate key 중에서 primary key로 선택된 키를 제외한 나머지 키.
- 비록 primary key는 아니지만, primary key 처럼 데이터를 구분하는
용도로 대신 사용할 수 있다고 해서 **대안 키(alternate key)** 라 부른다.
#### artificial key (인공키)
- Primary key로 사용하기에 적절한 컬럼을 찾을 수 없다면,
- 예) 게시글 : 제목, 내용, 작성자, 등록일, 조회수
- 이런 경우에 key로 사용할 컬럼을 추가한다.
- 보통 일련번호를 저장할 정수 타입의 컬럼을 추가한다.
- 예) 게시글 : 게시글 번호
- 대부분의 SNS 서비스들은 일련의 번호를 primary key 사용한다.
primary key
ㄴ pk 지정하기
#### primary key
- 테이블의 데이터를 구분할 때 사용하는 컬럼들이다.
- 줄여서 PK라고 표시한다.
- PK 컬럼을 지정하지 않으면 데이터가 중복될 수 있다.test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)

데이터 입력 테스트

ㄴ 중복 오류
ㄴ PK는 기본이 not null
primary key
ㄴ 한 개 이상의 컬럼을 PK로 지정하기
test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)
- 두 개 이상의 컬럼을 묶어서 PK로 선언하고 싶다면
각 컬럼에 대해서 개별적으로 PK를 지정해서는 안된다.
- 여러 개의 컬럼을 묶어서 PK로 지정하려면 별도의 문법을 사용해야 한다.
- constraint 제약조건이름 primary key (컬럼명, 컬럼명, ...)
- 제약조건이름은 생략 가능.
- 제약조건이름을 지정하지 않으면 이름이 자동으로 부여된다.
그래서 나중에 제약조건을 찾기 힘들다.
데이터 입력 테스트


ㄴ 이름과 나이가 같으면 중복되기 때문에 입력 거절됨
- 여러 개의 컬럼을 묶어서 PK로 사용하면 데이터를 다루기가 불편하다.
즉 데이터를 찾을 때 마다 name과 age 값을 지정해야 한다.
- 그래서 실무에서는 이런 경우 '학번'처럼 임의의 값을 저장하는 컬럼을 만들어 PK로 사용한다. (인공 키의 예!)
test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)

데이터 입력 테스트
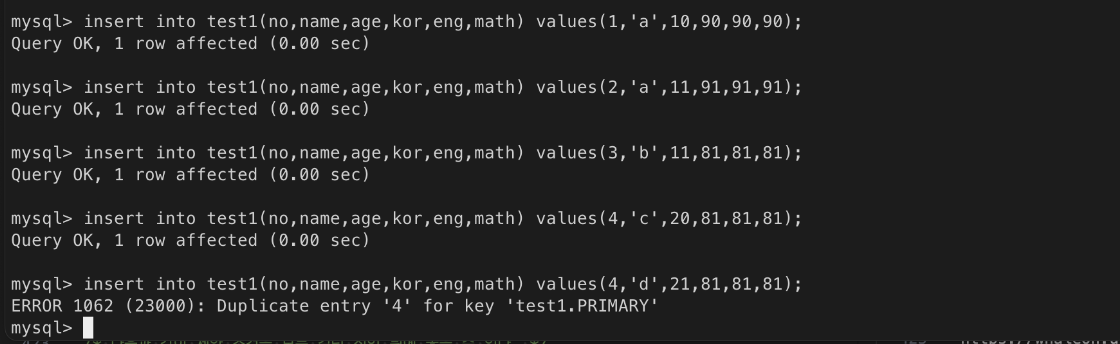
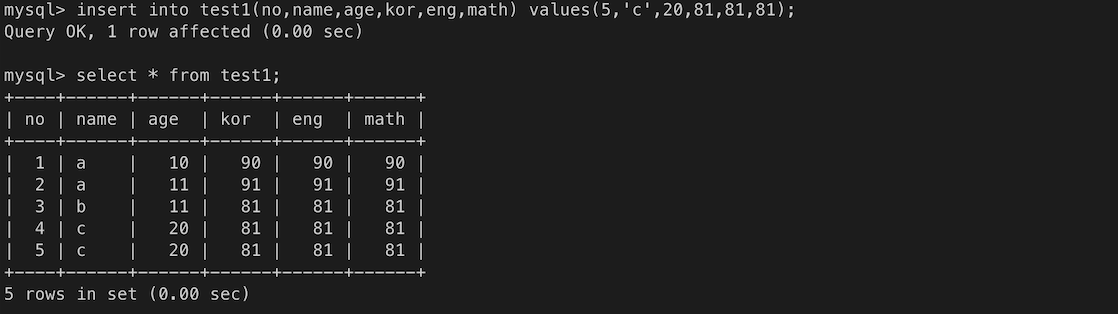
ㄴ 번호가 중복되었기 때문에 입력 거절
ㄴ 번호는 중복되지 않았지만, name과 age값이 중복되는 경우를 막을 수 없음
unique = alternate key(대안키)
- 위와 같은 경우를 대비해 준비된 문법이 unique이다.
- PK는 아니지만 PK처럼 중복되어서는 안되는 컬럼을 지정할 때 사용한다.
- 그래서 PK를 대신해서 사용할 수 있는 key라고 해서 "대안키(alternate key)"라고 부른다.
- 즉 대안키는 DBMS에서 unique 컬럼으로 지정한다.test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)

/* 다음과 같이 제약 조건을 모든 컬럼 선언 뒤에 놓을 수 있음 */
create table test1(
no int,
name varchar(20),
age int,
kor int,
eng int,
math int,
constraint primary key(no),
constraint test1_uk unique (name, age)
);/* 테이블 정의 다음에 제약 조건을 둘 수 있음 */
create table test1(
no int,
name varchar(20),
age int,
kor int,
eng int,
math int
);
alter table test1
add constraint test1_pk primary key (no);
alter table test1
add constraint test1_uk unique (name, age);데이터 입력 테스트



ㄴ 번호가 중복되었기 때문에 입력 거절
ㄴ 비록 번호가 중복되지 않더라도 name, age가 unique 컬럼으로 지정되었기 때문에 중복저장될 수 없음
index
##### index
- 검색 조건으로 사용되는 컬럼인 경우 따로 정렬해 두면 데이터를 찾을 때 빨리 찾을 수 있다.
- 특정 컬럼의 값을 A-Z 또는 Z-A로 정렬시키는 문법이 인덱스이다.
- DBMS는 해당 컬럼의 값으로 정렬한 데이터 정보를 별도의 파일로 생성한다.
- 보통 책 맨 뒤에 붙어있는 색인표와 같다.
- 인덱스로 지정된 컬럼의 값이 추가/변경/삭제 될 때 인덱스 정보도 갱신한다.
- 따라서 입력/변경/삭제가 자주 발생하는 테이블에 대해 인덱스 컬럼을 지정하면,
입력/변경/삭제 시 인덱스 정보를 갱신해야 하기 때문에
입력/변경/삭제 속도가 느려지는 문제가 있다.
- 대신 조회 속도는 빠르다.test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)
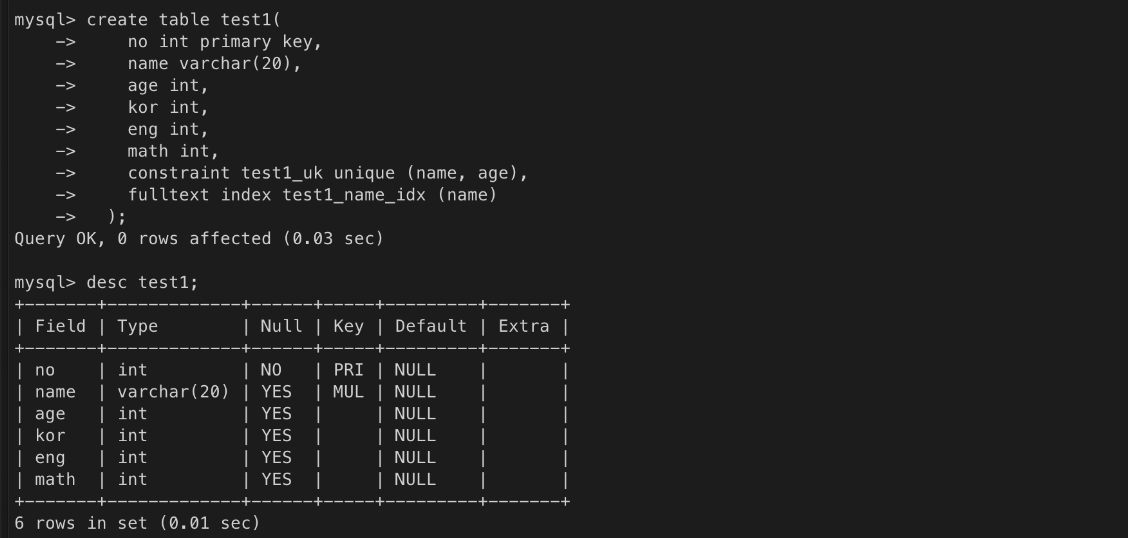
데이터 입력 테스트
- name 컬럼은 인덱스 컬럼으로 지정되었기 때문에
DBMS는 데이터를 추가하거나 삭제할 때 name 컬럼의 색인표를 갱신한다.
- 단점, 이런 이유로 이름으로 검색할 때 찾기 속도는 빠르지만,
입력,변경,삭제 속도는 느리게 된다.
인덱스 컬럼의 활용
#### 인덱스 컬럼의 활용
검색할 때 사용한다.select * from test1 where name = 'bbb';
테이블 변경
### 테이블 변경
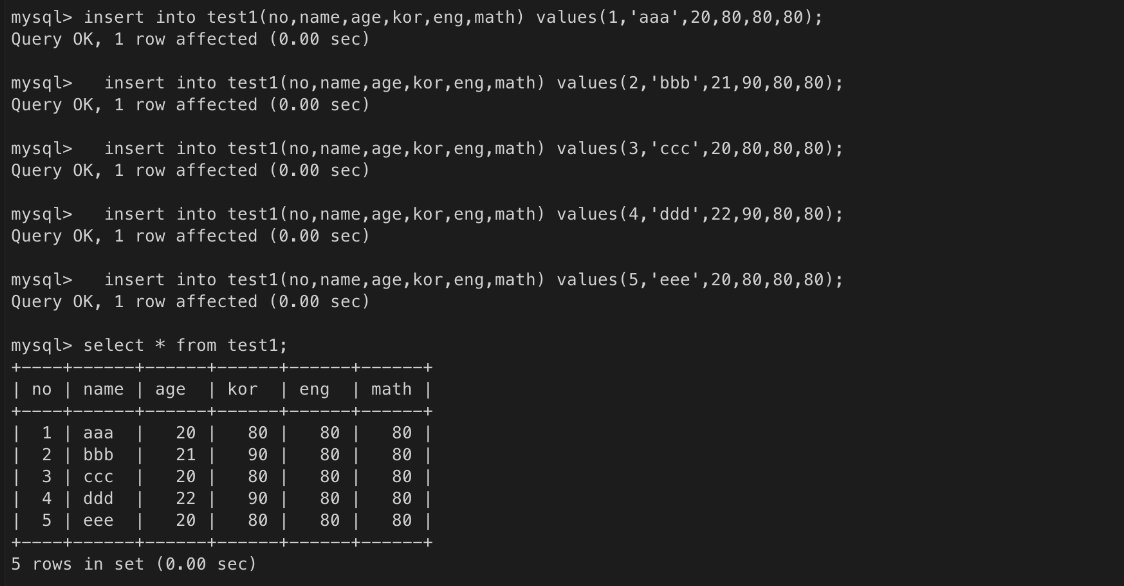
기존에 있는 테이블을 변경할 수 있다.test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)

테이블에 컬럼 추가
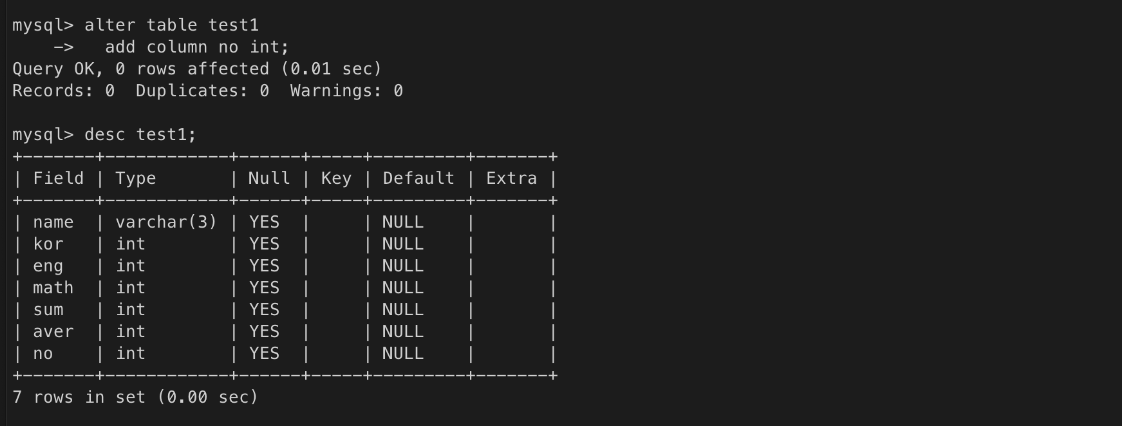


PK 컬럼 지정, UNIQUE 컬럼 지정, INDEX 컬럼 지정
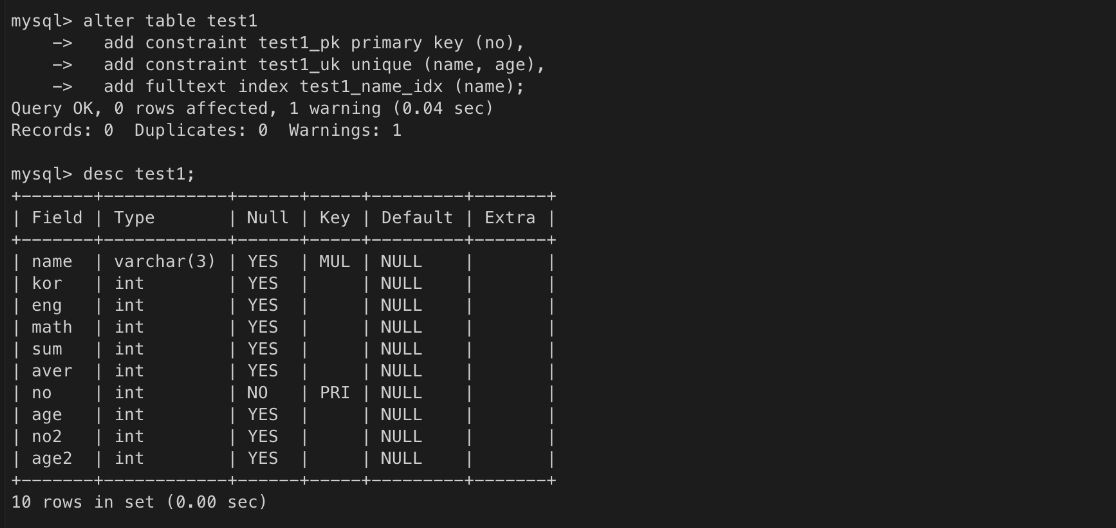
컬럼에 옵션 추가

입력 테스트


ㄴ name과 age의 값이 중복되기 때문에 입력 거절됨
컬럼 값 자동 증가
### 컬럼 값 자동 증가
- 숫자 타입의 PK 컬럼 또는 Unique 컬럼인 경우 값을 1씩 자동 증가시킬 수 있다.
- 즉 데이터를 입력할 때 해당 컬럼의 값을 넣지 않아도 자동으로 증가된다.
- 단 삭제를 통해 중간에 비어있는 번호는 다시 채우지 않는다.
즉 증가된 번호는 계속 앞으로 증가할 뿐이다.test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)

특정 컬럼의 값을 자동으로 증가하게 선언하기
ㄴ 단 반드시 key(primary key 나 unique)여야 함!!

ㄴ 아직 no가 pk가 아니기 때문에 오류

ㄴ 일단 no를 pk로 지정
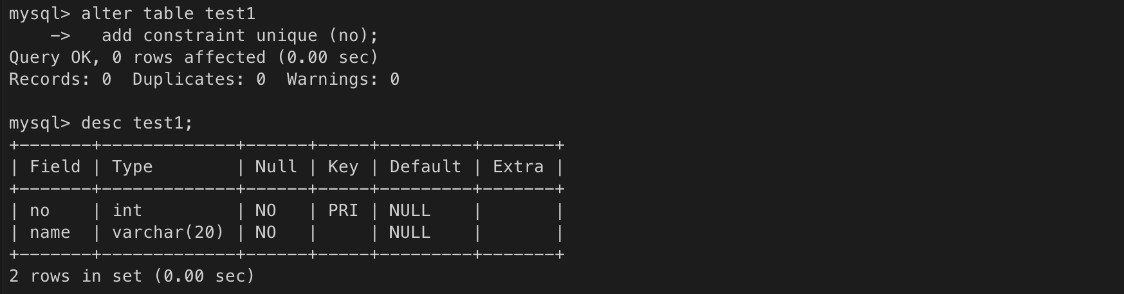
ㄴ no를 unique로 지정해도 됨

ㄴ 그런 후 auto_increment를 지정
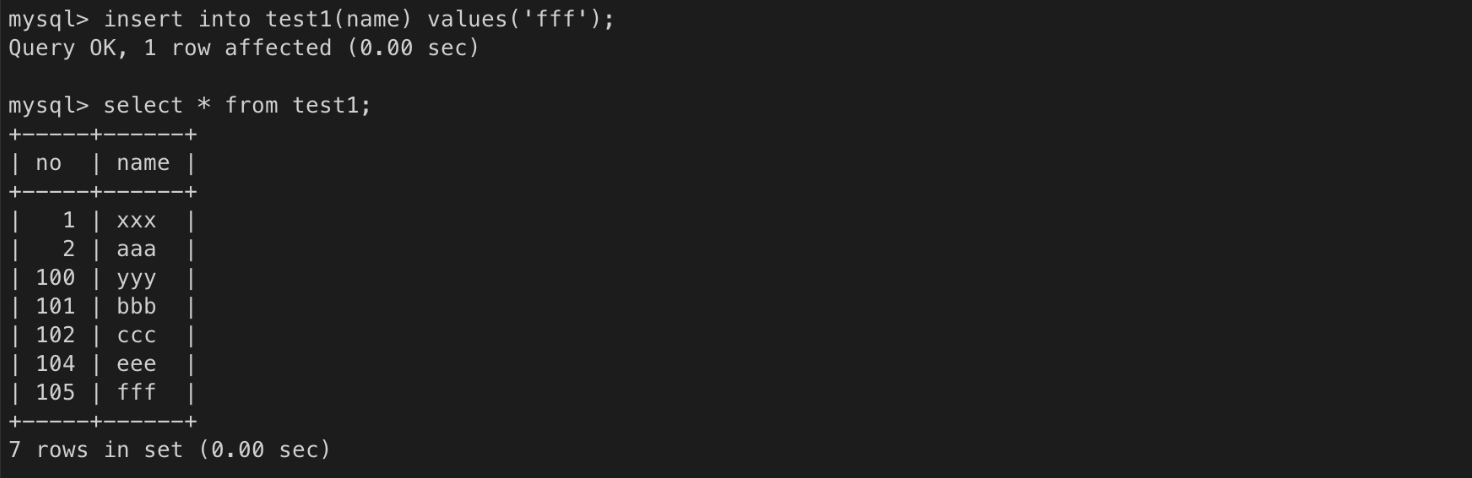
입력 테스트

ㄴ auto-increment 컬럼의 값을 직접 지정할 수 있음


ㄴ auto-increment 컬럼의 값을 생략하면 마지막 값을 증가시켜서 입력

insert into test1(name) values('bbb'); /* no는 101이 입력된다.*/
insert into test1(name) values('ccc'); /* no=102 */
insert into test1(name) values('ddd'); /* no=103 */

값을 삭제하더라도 auto-increment는 계속 앞으로 증가함

다른 DBMS의 경우 입력 오류가 발생하더라도 번호는 자동 증가하기 때문에
* 다음 값을 입력할 때는 증가된 값이 들어간다.
* 그러나 MySQL(MariaDB)는 증가되지 않는다.
뷰
## 뷰(view)
- 조회 결과를 테이블처럼 사용하는 문법
- select 문장이 복잡할 때 뷰로 정의해 놓고 사용하면 편리하다.test1 테이블 생성(drop 으로 기존 테이블 삭제 후 진행)

데이터 입력
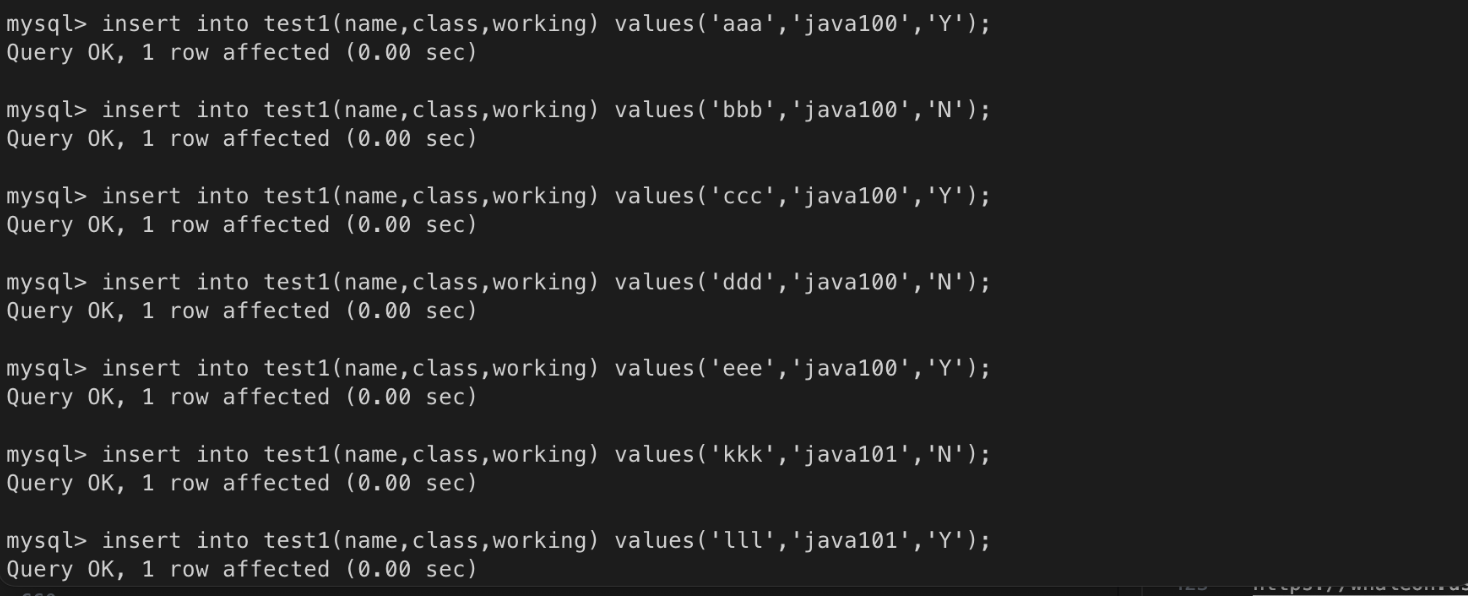

직장인만 조회

직장인만 조회한 결과를 가상 테이블로 만들기

view 데이터 삭제 테스트

- view가 참조하는 테이블에 데이터를 입력한 후 view를 조회하면?
=> 새로 추가된 컬럼이 함께 조회된다.
- 뷰를 조회할 때 마다 매번 select 문장을 실행한다.
=> 미리 결과를 만들어 놓는 것이 아니다.
- 일종의 조회 함수 역할을 한다.
- 목적은 복잡한 조회를 가상의 테이블로 표현할 수 있어 SQL문이 간결해진다.
뷰 삭제

제약 조건 조회
1) 테이블의 제약 조건 조회
select table_name, constraint_name, constraint_type
from table_constraints;
2) 테이블의 키 컬럼 정보 조회
select table_name, column_name, constraint_name
from key_column_usage;
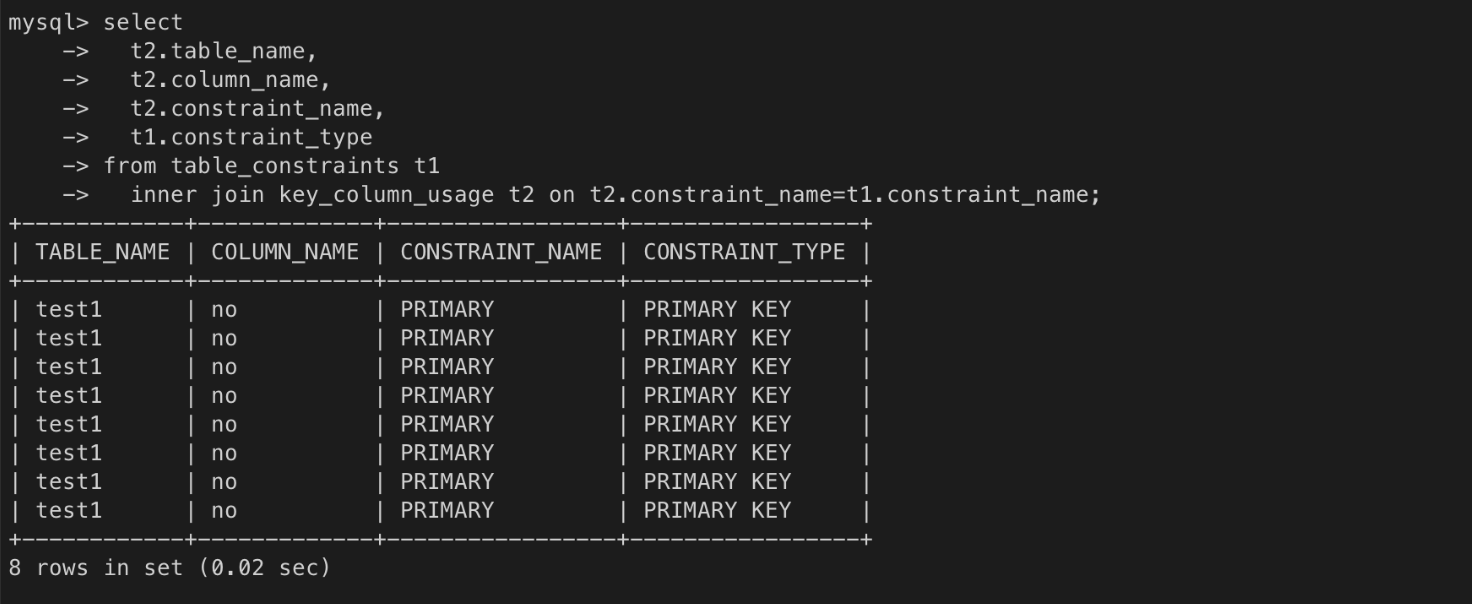
3) 테이블과 컬럼의 키 제약 조건 조회
select
t2.table_name,
t2.column_name,
t2.constraint_name,
t1.constraint_type
from table_constraints t1
inner join key_column_usage t2 on t2.constraint_name=t1.constraint_name;



테이블의 제약 조건 조회

테이블의 키 컬럼 정보 조회

테이블과 컬럼의 키 제약 조건 조회
'네이버클라우드 > JAVA 웹 프로그래밍' 카테고리의 다른 글
| JAVA 42일차 (2023-07-20) 자바 프로그래밍_DBMS_SQL - join(조인), 서브쿼리, 그룹 (0) | 2023.07.20 |
|---|---|
| JAVA 41일차 (2023-07-19) 자바 프로그래밍_DBMS_SQL - DML, DQL, Foreign Key (0) | 2023.07.20 |
| JAVA 39일차 (2023-07-17) 자바 프로그래밍_DBMS (0) | 2023.07.17 |
| JAVA 39일차 (2023-07-17) 자바 프로그래밍_45. 스레드 풀_개인프로젝트 - 마트 관리 시스템 (0) | 2023.07.17 |
| JAVA 39일차 (2023-07-17) 자바 프로그래밍_스레드 풀 사용법 (0) | 2023.07.17 |



