GridSearchCV (그리드서치)
ㄴ 하이퍼파라미터 튜닝 : 임의의 값들을 넣어 더 나은 결과를 찾는 방식
→ 수정 및 재시도하는 단순 작업의 반복
ㄴ 그리드 서치 : 수백 가지 하이퍼파라미터값을 한번에 적용 가능
ㄴ 그리드 서치의 원리 : 입력할 하이퍼파라미터 후보들을 입력한 후, 각 조합에 대해 모두 모델링해보고 최적의 결과가 나오는 하이퍼파라미터 조합을 확인
ㄴ 예를들어 하이퍼파라미터로 max_depth와 learning_rate를 사용한다고 가정
ㄴ 다음과 같이 하이퍼파라미터 별로 다양한 값들을 지정해줌

= > 그리드 서치로 적용하면 다음과 같이 9가지 조합이 만들어짐
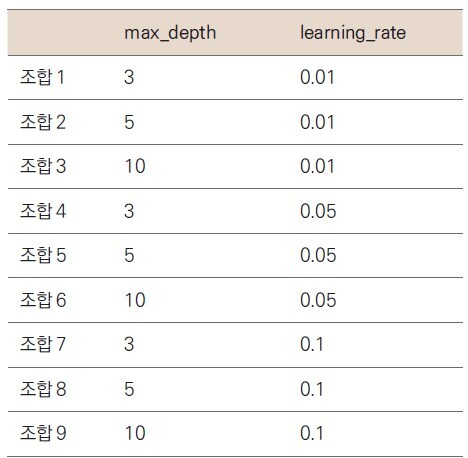
ㄴ 이렇게 9가지 조합을 각각 모델링
ㄴ 보통 그리드 서치에서는 교차검증의 횟수만큼 곱해진 횟수가 모델링됨
ㄴ 예를 들어 위의 9가지 조합에 KFold 값을 5로 교차검증을 한다면, 9 * 5 = 45회의 모델링을 진행
ㄴ 모델링 결과가 좋은 매개변수 조합을 알려주고, 해당 하이퍼파라미터셋으로 예측까지 지원
ㄴ 더 많은 하이퍼파라미터 종류와 더 많은 후보를 넣으면 더 좋은 결과를 얻을 수 있는 가능성도 높아지지만, 그만큼 학습 시간이 길어질 수 있으므로 적정 수준으로 설정해주는 게 좋음
ㄴ 그리드 서치 모듈은 sklearn 라이브러리의 model_selection에서 불러올 수 있음
ml13_gridSearchCV_iris.py
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
tf.random.set_seed(77) # weight 의 난수값 조정
# 1. 데이터
datasets = load_iris() # 다중분류
x = datasets['data']
y = datasets.target
x_train, x_test, y_train,y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42
)
# kfold
n_splits = 5 # 보통 홀수로 들어감
random_state = 42
kfold = StratifiedKFold(n_splits=n_splits, shuffle=True,
random_state=random_state)
# Scaler 적용
scaler = MinMaxScaler()
scaler.fit(x_train) # train 은 fit, transform 모두 해줘야 함
x = scaler.transform(x_train) # train 은 fit, transform 모두 해줘야 함
x = scaler.transform(x_test)
# [실습] 파라미터 튜닝 및 정리
param = [
{'n_estimators' : [100, 200], 'max_depth':[6, 8, 10, 12], 'n_jobs' : [-1, 2, 4]},
{'max_depth' : [6, 8, 10, 12], 'min_samples_split' : [2, 3, 5, 10]},
{'n_estimators' : [100, 200], 'min_samples_leaf' : [3, 5, 7, 10]},
{'min_samples_split' : [2, 3, 5, 10], 'n_jobs' : [-1, 2, 4]},
{'n_estimators' : [100, 200],'n_jobs' : [-1, 2, 4]}
]
# 2. 모델
from sklearn.model_selection import GridSearchCV
rf_model = RandomForestClassifier()
model = GridSearchCV(rf_model, param, cv=kfold, verbose=1,
refit=True, n_jobs=-1) # refit 는 False 가 default
# 3. 훈련
import time
start_time = time.time()
model.fit(x_train, y_train)
end_time = time.time() - start_time
print('최적의 파라미터 : ', model.best_params_)
print('최적의 매개변수 : ', model.best_estimator_)
print('best_score : ', model.best_score_) # 가장 좋은 score
print('model_score : ', model.score(x_test, y_test)) # 실제 데이터를 넣었을 때의 socre
print('걸린 시간 : ', end_time, '초')
# 최적의 파라미터 : {'max_depth': 6, 'min_samples_split': 5}
# 최적의 매개변수 : RandomForestClassifier(max_depth=6, min_samples_split=5)
# best_score : 0.95
# model_score : 1.0
# 걸린 시간 : 8.889904260635376 초
# 4. 평가, 예측
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # cv : corss validation
# print('cv acc : ', score) # kfold 에 있는 n_splits 숫자만큼 나옴
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
# print('cv pred : ', y_predict)
# cv pred : [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 1 0 2 2 2 2 2 0 0] # 0.8% 를 제외한 나머지 0.2 %
acc = accuracy_score(y_test, y_predict)
print('cv pred acc : ', acc)
# 결과
# SVC() 결과 acc : 0.9777777777777777
# LinearSVC() 결과 acc : 0.9777777777777777
# my 결과 acc : 1.0
# MinMaxScaler() 결과 acc : 0.9777777777777777
# ===============================================
# tree 결과 acc : 0.9555555555555556
# ===============================================
# ensemble 결과 acc : 0.9555555555555556
# ===============================================
# KFold 결과 acc : 1.0
# ====================================================================
# cv acc : [0.91666667 1. 0.91666667 0.83333333 1. ]
# cv pred acc : 0.9333333333333333
# stratifiedKFold cv pred acc : 0.9333333333333333 ㄴ 최적의 파라미터 알아보기
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
tf.random.set_seed(77) # weight 의 난수값 조정
# 1. 데이터
datasets = load_iris() # 다중분류
x = datasets['data']
y = datasets.target
x_train, x_test, y_train,y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42
)
# kfold
n_splits = 5 # 보통 홀수로 들어감
random_state = 42
kfold = StratifiedKFold(n_splits=n_splits, shuffle=True,
random_state=random_state)
# Scaler 적용
scaler = MinMaxScaler()
scaler.fit(x_train) # train 은 fit, transform 모두 해줘야 함
x = scaler.transform(x_train) # train 은 fit, transform 모두 해줘야 함
x = scaler.transform(x_test)
param = [
{'n_estimators' : [100, 200], 'max_depth':[6, 8, 10, 12], 'n_jobs' : [-1, 2, 4]},
{'max_depth' : [6, 8, 10, 12], 'min_samples_split' : [2, 3, 5, 10]}
]
# 2. 모델
from sklearn.model_selection import GridSearchCV
model = RandomForestClassifier(max_depth=6, min_samples_split=10)
# 3. 훈련
import time
start_time = time.time()
model.fit(x_train, y_train)
end_time = time.time() - start_time
print('걸린 시간 : ', end_time, '초')
# 최적의 파라미터 : {'max_depth': 6, 'min_samples_split': 10}
# 최적의 매개변수 : RandomForestClassifier(max_depth=6, min_samples_split=10) it=10)
# best_score : 0.95
# model_score : 1.0
# 4. 평가, 예측
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # cv : corss validation
# print('cv acc : ', score) # kfold 에 있는 n_splits 숫자만큼 나옴
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
# print('cv pred : ', y_predict)
# cv pred : [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 1 0 2 2 2 2 2 0 0] # 0.8% 를 제외한 나머지 0.2 %
acc = accuracy_score(y_test, y_predict)
print('cv pred acc : ', acc)
# 걸린 시간 : 0.10937929153442383 초
# cv pred acc : 1.0
# 결과
# SVC() 결과 acc : 0.9777777777777777
# LinearSVC() 결과 acc : 0.9777777777777777
# my 결과 acc : 1.0
# MinMaxScaler() 결과 acc : 0.9777777777777777
# ===============================================
# tree 결과 acc : 0.9555555555555556
# ===============================================
# ensemble 결과 acc : 0.9555555555555556
# ===============================================
# KFold 결과 acc : 1.0
# ====================================================================
# cv acc : [0.91666667 1. 0.91666667 0.83333333 1. ]
# cv pred acc : 0.9333333333333333
# stratifiedKFold cv pred acc : 0.9333333333333333ㄴ 최적의 파라미터 적용하기
= > model = RandomForestClassifier(max_depth=6, min_samples_split=10)
XGBoost
XGBoost 모델의 parmeters
참조 공식문서 https://xgboost.readthedocs.io/en/stable/parameter.html
XGBoost Parameters — xgboost 1.7.5 documentation
update: Starts from an existing model and only updates its trees. In each boosting iteration, a tree from the initial model is taken, a specified sequence of updaters is run for that tree, and a modified tree is added to the new model. The new model would
xgboost.readthedocs.io
'n_estimators': [100,200,300,400,500,1000]} #default 100 / 1~inf(무한대) / 정수
'learning_rate' : [0.1, 0.2, 0.3, 0.5, 1, 0.01, 0.001] #default 0.3/ 0~1 / learning_rate는 eta라고 해도 적용됨
'max_depth' : [None, 2,3,4,5,6,7,8,9,10] #default 3/ 0~inf(무한대) / 정수 => 소수점은 정수로 변환하여 적용해야 함
'gamma': [0,1,2,3,4,5,7,10,100] #default 0 / 0~inf
'min_child_weight': [0,0.01,0.01,0.1,0.5,1,5,10,100] #default 1 / 0~inf
'subsample' : [0,0.1,0.2,0.3,0.5,0.7,1] #default 1 / 0~1
'colsample_bytree' : [0,0.1,0.2,0.3,0.5,0.7,1] #default 1 / 0~1
'colsample_bylevel' : [0,0.1,0.2,0.3,0.5,0.7,1] #default 1 / 0~1
'colsample_bynode' : [0,0.1,0.2,0.3,0.5,0.7,1] #default 1 / 0~1
'reg_alpha' : [0, 0.1,0.01,0.001,1,2,10] #default 0 / 0~inf / L1 절대값 가중치 규제 / 그냥 alpha도 적용됨
'reg_lambda' : [0, 0.1,0.01,0.001,1,2,10] #default 1 / 0~inf / L2 제곱 가중치 규제 / 그냥 lambda도 적용됨
Jupyter 이용
ㄴ xgboost 에서 오류 날 경우 = > 설치가 안 돼있을 가능성이 높음
pip install xgboost
ml15_gridSearchCV_xgb_cancer.ipynb
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.preprocessing import MaxAbsScaler, RobustScaler
import tensorflow as tf
tf.random.set_seed(77) # weight 의 난수값 조정
# 1. 데이터
datasets = load_breast_cancer() # 다중분류
x = datasets['data']
y = datasets.target
x_train, x_test, y_train,y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42
)
# kfold
n_splits = 5 # 보통 홀수로 들어감
random_state = 42
kfold = StratifiedKFold(n_splits=n_splits, shuffle=True,
random_state=random_state)
# Scaler
scaler = MinMaxScaler()
scaler.fit(x_train) # train 은 fit, transform 모두 해줘야 함
x = scaler.transform(x_train) # train 은 fit, transform 모두 해줘야 함
x = scaler.transform(x_test)
# parameters
param = {
'n_estimators': [100,200], #default 100 / 1~inf(무한대) / 정수
'learning_rate' : [0.1, 0.01], #default 0.3/ 0~1 / learning_rate는 eta라고 해도 적용됨
'max_depth' : [3,4,5], #default 3/ 0~inf(무한대) / 정수 => 소수점은 정수로 변환하여 적용해야 함
'gamma': [4], #default 0 / 0~inf
'min_child_weight': [0,0.1,0.5], #default 1 / 0~inf
'subsample' : [0,0.1,0.2], #default 1 / 0~1
'colsample_bytree' : [0,0.1], #default 1 / 0~1
'colsample_bylevel' : [0,0.1], #default 1 / 0~1
'colsample_bynode' : [0,0.1], #default 1 / 0~1
'reg_alpha' : [0, 0.1], #default 0 / 0~inf / L1 절대값 가중치 규제 / 그냥 alpha도 적용됨
'reg_lambda' : [1] #default 1 / 0~inf / L2 제곱 가중치 규제 / 그냥 lambda도 적용됨
}
# 2. 모델
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
xgb = XGBClassifier(colsample_bylevel= 0, colsample_bynode = 0,
colsample_bytree = 0.1, gamma = 4, learning_rate = 0.1,
max_depth = 3, min_child_weight = 0, n_estimators = 200,
reg_alpha = 0, reg_lambda = 1, subsample = 0.2)
# model = GridSearchCV(xgb, param, cv=kfold,
# refit=True, verbose=1, n_jobs=-1)
# 3. 훈련
import time
start_time = time.time()
model.fit(x_train, y_train)
end_time = time.time() - start_time
print('최적의 파라미터 : ', model.best_params_)
print('최적의 매개변수 : ', model.best_estimator_)
print('best_score : ', model.best_score_) # 가장 좋은 score
print('model_score : ', model.score(x_test, y_test)) # 실제 데이터를 넣었을 때의 socre
print('걸린 시간 : ', end_time, '초')
# 4. 평가, 예측
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # cv : corss validation
# print('cv acc : ', score) # kfold 에 있는 n_splits 숫자만큼 나옴
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
acc = accuracy_score(y_test, y_predict)
print('cv pred acc : ', acc)ㄴ 최적의 파라미터 찾아서 적용
최적의 파라미터 : {'colsample_bylevel': 0, 'colsample_bynode': 0, 'colsample_bytree': 0.1, 'gamma': 4,
'learning_rate': 0.1, 'max_depth': 3, 'min_child_weight': 0, 'n_estimators': 200,
'reg_alpha': 0, 'reg_lambda': 1, 'subsample': 0.2}ㄴ 최적의 파라미터 찾기
xgb = XGBClassifier(colsample_bylevel= 0, colsample_bynode = 0,
colsample_bytree = 0.1, gamma = 4, learning_rate = 0.1,
max_depth = 3, min_child_weight = 0, n_estimators = 200,
reg_alpha = 0, reg_lambda = 1, subsample = 0.2)ㄴ 파라미터 적용 시 이렇게 형식 변환하여 적용
LightGBM 모델의 parmeters
참조 공식문서 https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html
Parameters Tuning — LightGBM 3.3.5.99 documentation
num_leaves. This is the main parameter to control the complexity of the tree model. Theoretically, we can set num_leaves = 2^(max_depth) to obtain the same number of leaves as depth-wise tree. However, this simple conversion is not good in practice. The re
lightgbm.readthedocs.io
대체로 XGBoost와 하이퍼 파라미터들이 비슷하지만 leaf-wise 방식의 하이퍼 파라미터가 존재함
num_leaves : 하나의 트리가 가질 수 있는 최대 리프 개수
min_data_in_leaf : 오버피팅을 방지할 수 있는 파라미터, 큰 데이터셋에서는 100이나 1000 정도로 설정
feature_fraction : 트리를 학습할 때마다 선택하는 feature의 비율
n_estimators : 결정 트리 개수
learning_rate : 학습률
reg_lambda : L2 규제
reg_alpha : L1규제
max_depth : 트리 개수 제한
Catboost
Catboost 모델의 parmeters
참조 공식문서 https://catboost.ai/en/docs/concepts/python-reference_catboost_grid_search
grid_search
A simple grid search over specified parameter values for a model. Note. After searching, the model is trained and ready to use. Method call format.
catboost.ai
CatBoost 평가 지표 최적화에 가장 큰 영향을 미치는 하이퍼파라미터는 learning_rate, depth, l2_leaf_reg 및
random_strength
learning_rate: 학습률
depth: 각 트리의 최대 깊이로 과적합을 제어
l2_leaf_reg: L2 정규화(regularization) 강도로, 과적합을 제어
colsample_bylevel: 각 트리 레벨에서의 피처 샘플링 비율
n_estimators: 생성할 트리의 개수
subsample: 각 트리를 학습할 때 사용할 샘플링 비율
border_count: 수치형 특성 처리 방법
ctr_border_count: 범주형 특성 처리 방법= > learning_rate, depth, l2_leaf_reg, random_strength = > 가장 영향을 많이 미침
Jupyter 이용
ㄴ catboost 에서 오류 날 경우 = > 설치가 안 돼있을 가능성이 높음
pip install catboost
ml16_gridSearchCV_cat_iris.ipynb
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.preprocessing import MaxAbsScaler, RobustScaler
import tensorflow as tf
tf.random.set_seed(77) # weight 의 난수값 조정
# 1. 데이터
datasets = load_iris() # 다중분류
x = datasets['data']
y = datasets.target
x_train, x_test, y_train,y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42
)
# kfold
n_splits = 5 # 보통 홀수로 들어감
random_state = 42
kfold = StratifiedKFold(n_splits=n_splits, shuffle=True,
random_state=random_state)
# Scaler
scaler = MinMaxScaler()
scaler.fit(x_train) # train 은 fit, transform 모두 해줘야 함
x = scaler.transform(x_train) # train 은 fit, transform 모두 해줘야 함
x = scaler.transform(x_test)
# parameters
param = {
'learning_rate': [0.1, 0.01, 0.001],
'depth': [3, 5, 6, 9],
'l2_leaf_reg': [1, 3, 5, 7],
# 'colsample_bylevel': [1],
# 'n_estimators': [100],
# 'subsample': [3, 5],
# 'border_count': [3]
}
# 2. 모델
from catboost import CatBoostClassifier
from sklearn.model_selection import GridSearchCV
cat = CatBoostClassifier() # 성능 가장 좋음
model = GridSearchCV(cat, param, cv=kfold,
refit=True, verbose=1, n_jobs=-1)
# 3. 훈련
import time
start_time = time.time()
model.fit(x_train, y_train)
end_time = time.time() - start_time
print('최적의 파라미터 : ', model.best_params_)
print('최적의 매개변수 : ', model.best_estimator_)
print('best_score : ', model.best_score_) # 가장 좋은 score
print('model_score : ', model.score(x_test, y_test)) # 실제 데이터를 넣었을 때의 socre
print('걸린 시간 : ', end_time, '초')
# 최적의 파라미터 : {'depth': 3, 'l2_leaf_reg': 1, 'learning_rate': 0.001}
# 최적의 매개변수 : <catboost.core.CatBoostClassifier object at 0x7f1b5d478f70>
# best_score : 0.9416666666666668
# model_score : 1.0
# 걸린 시간 : 144.4269983768463 초
# 4. 평가, 예측
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # cv : corss validation
# print('cv acc : ', score) # kfold 에 있는 n_splits 숫자만큼 나옴
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
acc = accuracy_score(y_test, y_predict)
print('cv pred acc : ', acc)
# cv pred acc : 0.9666666666666667
ml16_gridSearchCV_cat_california.ipynb
import numpy as np
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.preprocessing import MaxAbsScaler, RobustScaler
import tensorflow as tf
tf.random.set_seed(77) # weight 의 난수값 조정
# 1. 데이터
datasets = fetch_california_housing() # 다중분류
x = datasets['data']
y = datasets.target
x_train, x_test, y_train,y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42
)
# kfold
n_splits = 5 # 보통 홀수로 들어감
random_state = 42
kfold = KFold(n_splits=n_splits, shuffle=True,
random_state=random_state)
# Scaler
scaler = MinMaxScaler()
scaler.fit(x_train) # train 은 fit, transform 모두 해줘야 함
x = scaler.transform(x_train) # train 은 fit, transform 모두 해줘야 함
x = scaler.transform(x_test)
# parameters
param = {
# 'learning_rate': [0.1, 0.01, 0.001],
# 'depth': [3, 5, 6, 9],
# 'l2_leaf_reg': [1, 3, 5, 7],
# 'colsample_bylevel': [1],
# 'n_estimators': [100],
# 'subsample': [3, 5],
# 'border_count': [3]
'learning_rate': [0.1, 0.5, 1], # controls the learning rate
'depth': [3, 4, 5], # controls the maximum depth of the tree
'l2_leaf_reg': [2, 3, 4], # controls the L2 regularization term on weights
'colsample_bylevel': [0.1, 0.2, 0.3], # specifies the fraction of columns to be randomly sampled for each level
'n_estimators': [100, 200], # specifies the number of trees to be built
'subsample': [0.1, 0.2, 0.3], # specifies the fraction of observations to be randomly sampled for each tree
'border_count': [32, 64, 128],# specifies the number of splits for numerical features
'bootstrap_type': ['Bernoulli', 'MVS']
}
# 2. 모델
from catboost import CatBoostRegressor
from sklearn.model_selection import GridSearchCV
cat = CatBoostRegressor() # 성능 가장 좋음
model = GridSearchCV(cat, param, cv=kfold,
refit=True, verbose=1, n_jobs=-1)
# 3. 훈련
import time
start_time = time.time()
model.fit(x_train, y_train)
end_time = time.time() - start_time
print('최적의 파라미터 : ', model.best_params_)
print('최적의 매개변수 : ', model.best_estimator_)
print('best_score : ', model.best_score_) # 가장 좋은 score
print('model_score : ', model.score(x_test, y_test)) # 실제 데이터를 넣었을 때의 socre
print('걸린 시간 : ', end_time, '초')
# 4. 평가, 예측
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # cv : corss validation
# print('cv acc : ', score) # kfold 에 있는 n_splits 숫자만큼 나옴
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
r2 = r2_score(y_test, y_predict)
print('cv pred r2 : ', r2)'네이버클라우드 > AI' 카테고리의 다른 글
| AI 7일차 (2023-05-16) 인공지능 기초 _머신러닝 - Voting(보팅) (0) | 2023.05.16 |
|---|---|
| AI 7일차 (2023-05-16) 인공지능 기초 _머신러닝 - Bagging(배깅) (0) | 2023.05.16 |
| AI 6일차 (2023-05-15) 인공지능 기초 _머신러닝 - Boosting 계열의 모델 (0) | 2023.05.16 |
| AI 6일차 (2023-05-15) 인공지능 기초 _머신러닝 - Feature Importances (0) | 2023.05.15 |
| AI 6일차 (2023-05-15) 인공지능 기초 _머신러닝 - K-Fold 와 StratifiedKFold (0) | 2023.05.15 |



